[Paper] Wide & Deep Learning for Recommender Systems
Posted on June 01, 2019 in AI.ML. View: 1,901
結論寫在前面
以往認為deep learning有辦法完全取代feature engineering,Google在2016年寫下的這篇paper,指出在數據相對稀疏(sparse)的情況下feature engineering仍然有其重要性,此篇paper使用聯合訓練(jointly train)deep和wide結構的方法,得到比純粹deep或純粹wide的效果還好的成果,這裡的wide就是我們一般所說的feature engineering。
Memorization and Generalization
Memorization指的就是wide learning,此部分的產生需要較多的人為參與,也就是feature engineering,通常我們會依照人為的認知、或是統計數據、或是反覆實驗的結果,將一些有關聯性的變數進行cross-product以讓model得以「記住」這些相關性,通常這種基於memorization的結構會比較具有解釋性。
Generalization指的就是deep Learning,此部份與wide learning相反,結構本身因為它的深度結構,等效於多次的non-linear transformation,也因此model自身在學習的過程就會將隱藏的feature組合給找出來,所以不用太多的人為參與,所以它會比較「一般化」。
近年來deep learning大行其道,所以人們往往認為已經沒有必要再去做feature engineering了,只需要設定好深度結構,機器自動會去學出我們人類已知的feature組合,甚至學出隱藏的feature組合,但這篇paper指出這樣的想法是錯誤的,Wide結構有其重要性。
推薦問題
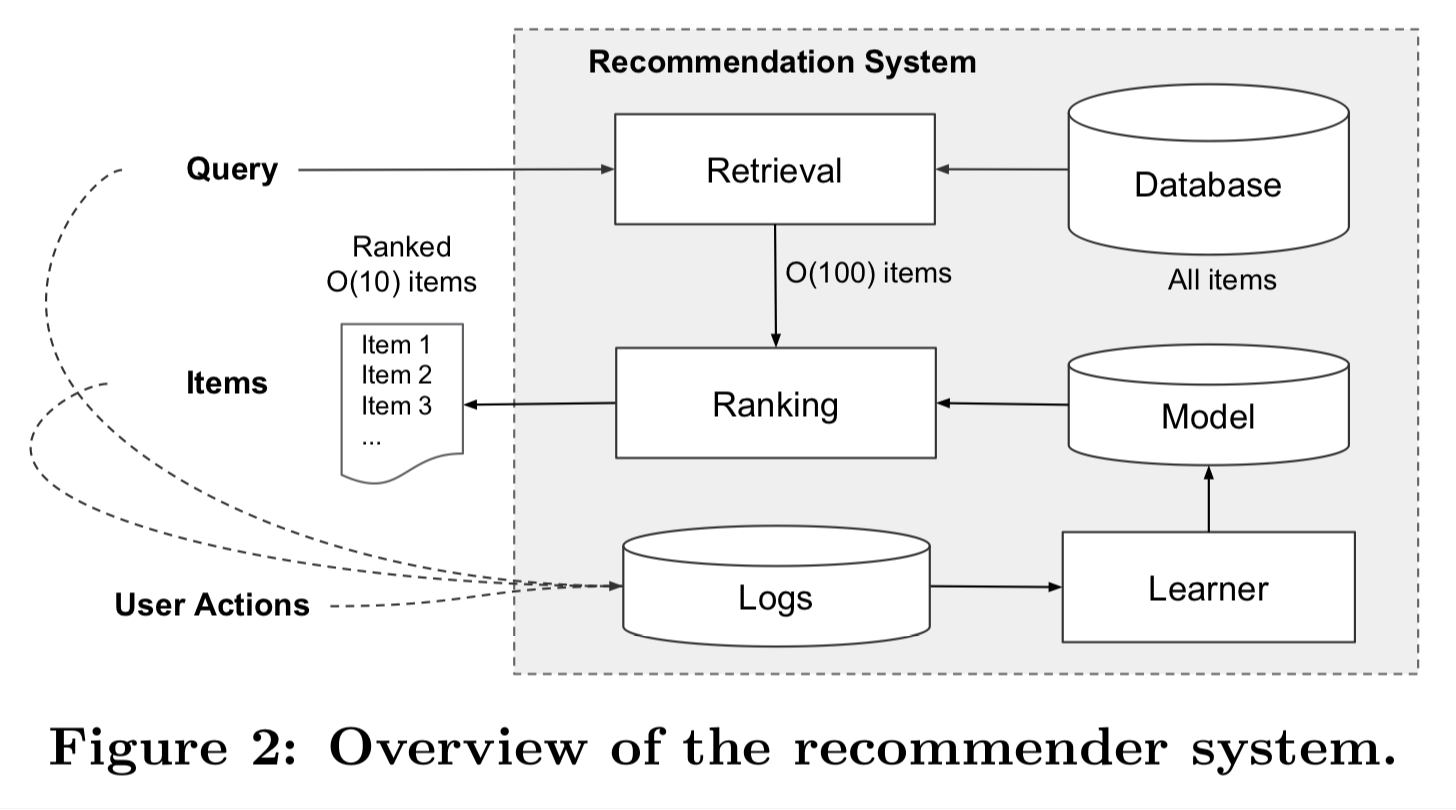
這篇paper想要解決的是Google Play上的app推薦問題,如上圖所示,我們透過Learner從Logs中學習出一個Model,接下來使用這個Model為app打上推薦的分數,再進行排序,不過因為我們要評分的app超過一百萬個以上,在幾十 miliseconds 的限制推薦時間之下,根本是來不及的,所以這邊需要先進行Retrieval,我們並不是把所有的app都評過一次分數,而是Retrieval事先挑選出一些app再進行評分,挑選方式是使用其他的machine learning方法或是人為規則限定。
精神
基於memorization的推薦系統,通常比較容易推薦出過去曾經被使用者作用過的app;相反的,基於generalization的推薦系統,它的多樣性(diversity )會更好一點,更可能去推薦一些不曾使用過或很少被使用過的app,以下詳細解釋。
對於大型推薦系統而言,我們經常使用wide learning搭配logistic regression,因為它簡單、可擴充和可解釋。舉個cross-product的例子: AND(user_installed_app=netflex, impression_app=pandora) ,這個feature組合就相當有可解釋性,它指的是同時滿足使用者曾經安裝過netflex和接下來會顯示pandora,相當直觀。但也因為這種feature組合是基於過去資料,造成model難以學出過去沒出現過的組合,所以多樣性會較差。
另一方面,embedding-base models,例如:factorization machines或deep neural networks,能利用低維度的embedding vector去學出更一般的行為,讓過去沒出現過的組合更有可能出線,進而增加多樣性。其實說穿了,embedding的概念就是降維,當今天維度降低、輸入參數變少,就會迫使系統去學更一般、更重要的規則。
不過embedding-base models如果遇到稀疏(sparse)的情形就會很慘,因為資料稀疏,一般化的規則出現次數不怎麼多,所以容易過度一般化(over-generalize),然後就學出完全不相關的東西。
綜上所述,在稀疏情況下的推薦系統,最好要同時考慮memorization和generalization,作者這裡是使用聯合訓練(jointly train),也就是將兩種系統綁在一起優化,這和ensemble models不一樣,ensemble models是不同model各自訓練再結合,這樣做的缺點是需要更多的model參數。
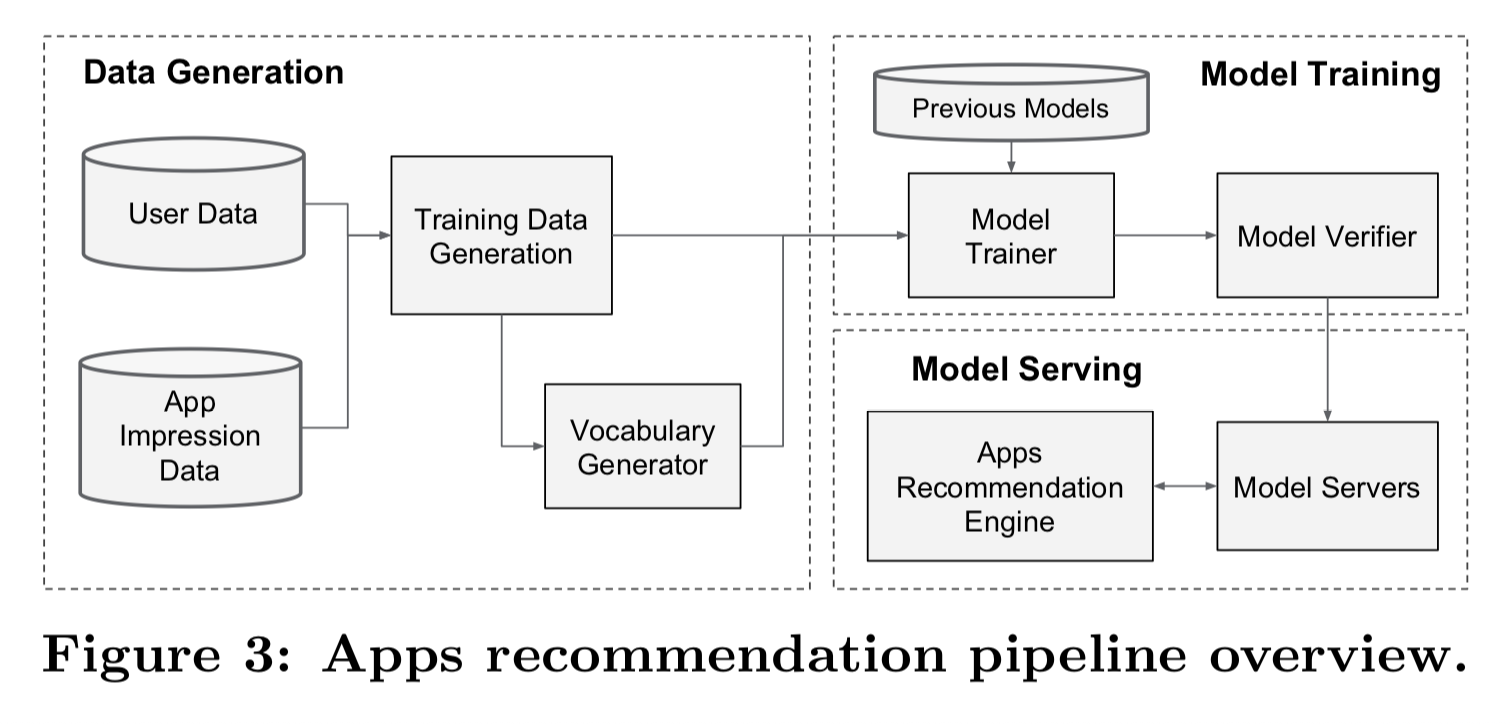
Wide & Deep Learning: 資料處理
如上圖所示,我們採用User Data和App Impression Data,接下來利用Vocabulary Generator把categorical feature轉成整數ID,categorical feature的labels不是0就是1,另外continuous features則會進行normalization,將labels映射到 [0, 1] 之間,normalization的方法是採用分位數(quantiles)方法,將feature的數據分成 \(n_q\) 位數,每個級距內的數值映射到 \((i-1)/(n_q-1)\) ,\(i\) 指的是它的分位數落在哪裡。
Wide & Deep Learning: 模型訓練
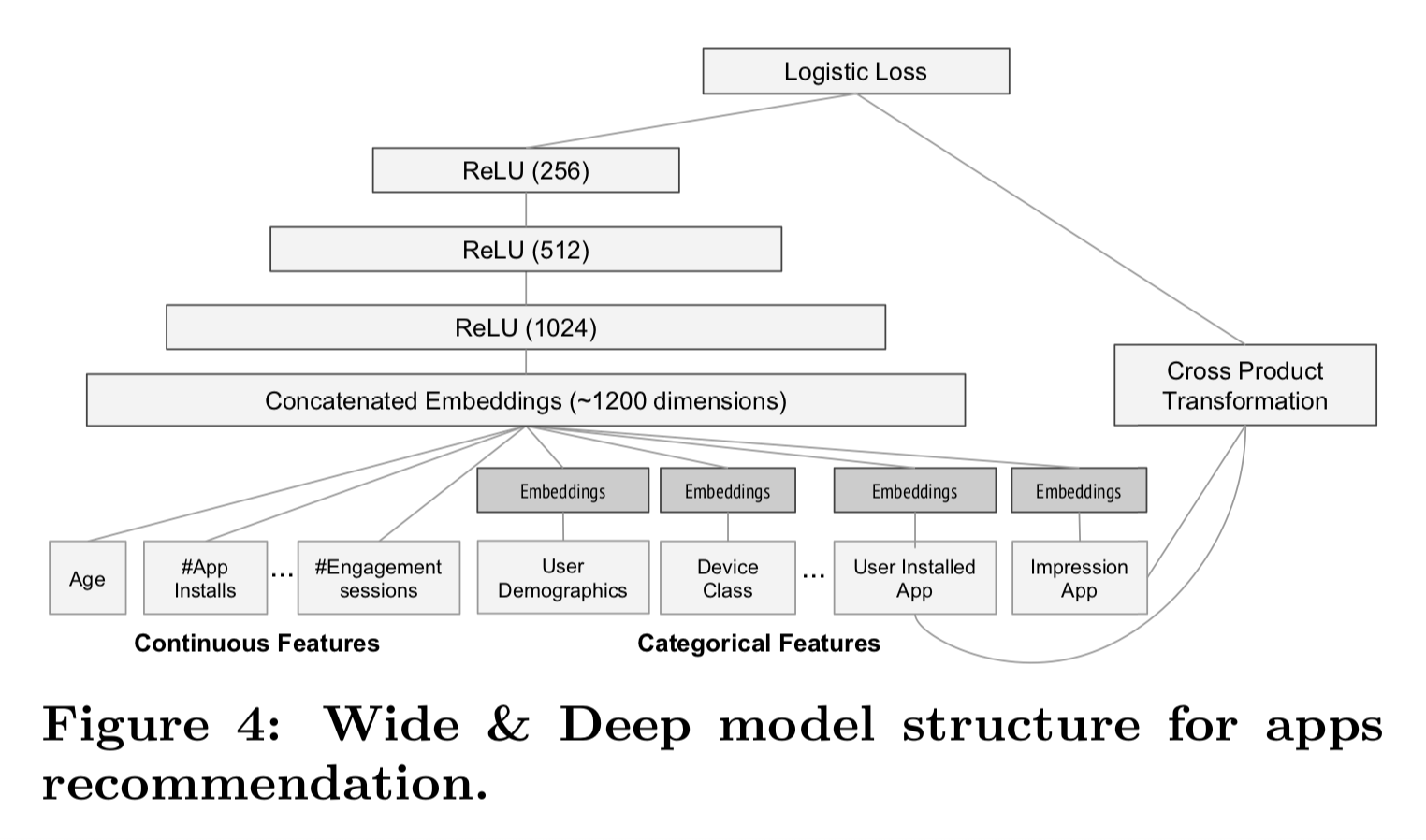
上圖是model structure,左側是Deep的部分,右側是Wide的部分。
Wide & Deep Learning是採用back-propagation來優化「評分」,而Wide的部分,使用FTRL (Follow-the-regularized-leader) algorithm搭配L1 regularization當作optimizer來優化,這種算法會使得model weights更稀疏,詳細解釋未來需要整整一篇來介紹;Deep的部分,則是使用AdaGrad當作optimizer來優化。
來更仔細的看Deep部份的結構,從下而上看起,每個categorical features都會經過一個降維轉化,轉化成32維的embedding vector,降維迫使系統學習更一般的規則。接下來把所有的feature包含continuous feature和categorical features連結在一起,成為Concatenated Embeddings,這大概有1200維左右。這個Concatenated Embeddings接下來會餵進去三層的ReLU,就完成了。
實驗結果
Offline實驗的結果,純粹Wide當作控制組它的AUC為\(0.726\),純粹Deep的AUC為\(0.722\),稍差於控制組,Wide & Deep的AUC為\(0.728\),稍好於控制組。Online AB分流實驗差異比較顯著,與控制組(純粹Wide)相比,純粹Deep增加了\(2.9\%\) 的獲取率,Wide & Deep增加了 \(3.9\%\) 的獲取率,所以確實Wide & Deep是效果最好的。
眼尖的讀者應該發現一個奇怪的地方,純粹Deep在offline明明比控制組差,為何在online會比控制組好,可能的原因是offline實驗數據是固定的,所以當我增加更多的多樣性,對於offline是沒什麼幫助的,但是對於online而言多樣性可能造成用戶更多的獲取,從這裡我們也看到多樣性的重要性。