實作Tensorflow (4):Autoencoder
Posted on November 18, 2017 in AI.ML. View: 14,028
Autoencoder是一個Neurel Network重要的工具,我個人認為它還漂亮的呈現Neurel Network的強大。
本單元程式碼Autoencoder部分可於Github下載,De-noise Autoencoder部分可於Github下載。
Autoencoder觀念解析
在「機器學習技法」的系列文章,我也曾經介紹過Autoencoder,可以搭配這篇服用。
Autoencoder概念很簡單,就是做資訊的壓縮,概念是這樣的,當我在一層當中使用神經元愈多,可以儲存的資訊量也就愈多,相反的神經元越少,可以儲存的資訊量越少,如果我要使用Neurel Network作資料壓縮的話,我希望的是可以使用比原本更少的資訊量來儲存,如果原本是一張MNIST的圖,有28x28=784個Pixels,所以可以想知,如果我要作壓縮就要使得壓縮後的神經元可以比784個更少。
但是什麼都不做我們就可以平白無故的做到壓縮?當然不行,我們還得從資料中找到一些規律,套用這些規律把多餘的東西去除,留下精髓,我們才可以把資料作壓縮,所以在實作上我們會建立一個神經元由大到小的Neurel Network,逐步的轉換,逐步的壓縮資訊。
那麼壓縮的目的是為了什麼?當然是有辦法還原回去原本狀態,這樣的壓縮才是有意義的,例如:將文檔打包成RAR,檔案大小會變小,但如果實際要再使用這個檔案,那就必須先做解壓縮,然後還原回去原本的檔案,這裡的還原率必須是百分之一百的,Autoencoder一樣的有一個機制可以還原,在實作上我們會建立一個神經元由小到大的Neurel Network,逐步的還原回去原本的狀態。
因此一個Autoencoder的圖像就出現了,我們需要有一組「Encoder」來逐步的壓縮,最後留下非常精簡的「Embedding Code」,而這組「Embedding Code」可以再經由「Decoder」還原回去原本的樣子,那我們怎麼讓他自己產生「Encoder」和「Decoder」呢?把原本的Input當作Output的目標答案去訓練Neurel Network就可以了,這就是Autoencoder巧妙的地方。
不管是「Encoder」還是「Decoder」他們的權重是可以調整的,所以如果你將Encoder+Decoder的結構建立好並搭配Input當作Output的目標答案,它在Training的過程,Autoencoder會試著找出最好的權重來使得資訊可以盡量完整還原回去,所以Autoencoder可以自行找出了Encoder和Decoder。
Encoder的效果等同於做Dimension Reduction,Encoder轉換原本數據到一個新的空間,這個空間可以比原本Features描述的空間更能精簡的描述這群數據,而中間這層Layer的數值Embedding Code就是新空間裡頭的座標,有些時候我們會用這個新空間來判斷每筆Data之間彼此的接近程度。
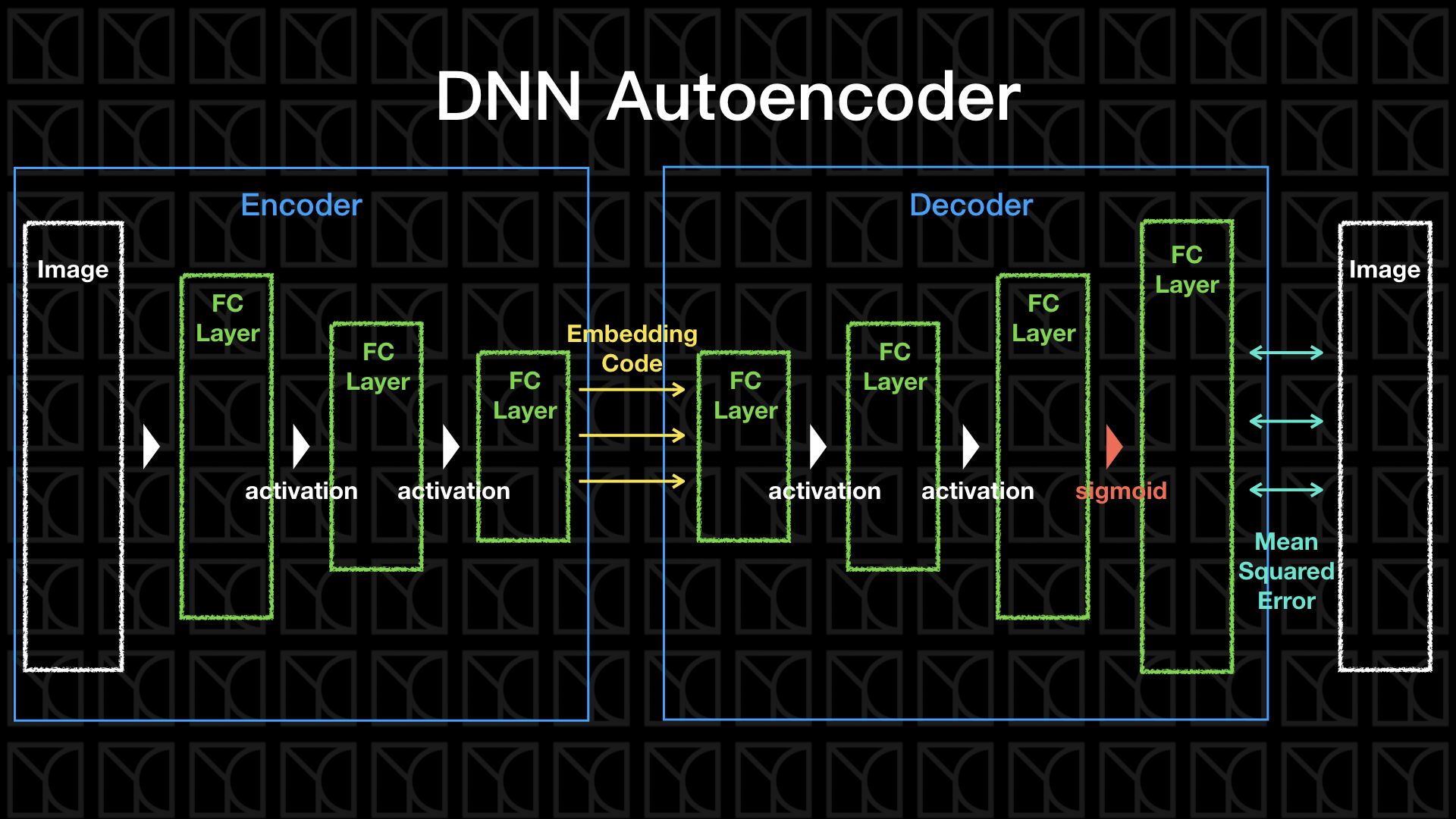
Autoencoder程式碼
實現Autoencoder和之前DNN並沒有太大的差異,只有兩點要特別提醒一下。
第一點,以下我會特別把encoder額外的在structure裡頭輸出出來,並且增加新的函數encode,讓使用者可以使用Train好的Encoder來做Encode。
第二點,以下的Regularizer不是採用單純的L2 Regularizer,我將會使用Weight-Elimination L2 Regularizer,這個Regularizer的好處是會使得權重接近Sparse,也就是說權重會留下比較多的0,這有一個好處,就是每個神經元彼此之間的依賴減少了,因為內積(評估相依性)時有0的那個維度將不會有所貢獻。
Weight-Elimination L2 Regularizer有這樣的效果原因是這樣的,L2 Regularizer在抑制W的方法是,如果\(W\)的分量大的話就抑制多一點,如果分量小就抑制少一點(因為\(W^2\)微分為一次),所以最後會留下很多不為0的微小分量,不夠Sparse,這樣的Regularization顯然不夠好,L1 Regularizer可以解決這個問題(因為在大部分位置微分為常數),但不幸的是它無法微分,沒辦法作Backpropagation,所以就有了L2 Regularizer的衍生版本,
Weight-elimination L2 regularizer:
這麼一來不管W大或小,它受到抑制的值大小接近的 (Weight-elimination L2 regularizer微分為 \(-1\)次方),因此就可以使得部分\(W\)可以為\(0\),達成Sparse的目的。
那為什麼我要特別在Autoencoder講究Sparse特性呢?原因是我們現在正在做的事是Dimension Reduction,做這件事就好像是替原本空間找出新的軸,而這個軸的數量比原本空間軸的數量來得小,達到Dimension Reduction的效果,所以我們會希望這個新的軸彼此間可以不要太多的依賴,什麼是不依賴呢?直角座標就是最不依賴的座標系,X軸和Y軸內積為0,這樣的軸展開的效率是最好的,所以我們希望在做Regularization的同時可以減少新軸的彼此間的依賴性。
1 2 3 4 5 6 7 8 9 10 11 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 | |
測試Autoencoder
1 2 3 4 5 6 | |
1 2 3 4 5 6 7 8 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | |

上面圖中上排是進去Autoencoder之前的圖片,下排是經過Autoencoder後的圖片,效果是不是很驚人!大致都有辦法還原回去原圖。但是仍有幾張圖還原的不是很好,做個Regularization看看能不能解決這個問題。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | |

似乎看起來是有效果的,數字還原的比較清晰。
壓縮碼Code與視覺化
剛剛提到在Autoencoder前半段是一個Encoder,所以我們可以利用這個Encoder來做壓縮,會得到一個Code,在上面的這個例子,這個Code總共有4個值,因為中間層有4個神經元,可以把這個Code看成Dimension Reduction的結果,原本一張圖代表的是28x28=784個維度下的一個點,現在經過轉換後變成是4個維度下的一個點,而我們會直覺的認為同樣一群的數字圖形應該會有較高的相似度,所以在4個維度之下,同樣的數字圖片應該會彼此靠近的比較近,甚至聚成一團。
我想要驗證一下這件事,我們需要先圖像化,不過卻卡在維度太高的問題,人類無法想像高於3個維度以上的空間,也沒辦法將它視覺化,這個時候我們需要再做一次的Dimension Reduction,將維度降到低於3才可以視覺化,那一般手法是使用PCA來做這件事,有關於PCA我之前已經介紹過,請參考這篇,如此一來就可以在4個維度中切一個重要的截面來視覺化這些數據。不過記得喔!4個維度才是真正可以表示這群資料,做PCA只是為了畫圖而做的粗略轉換而已。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
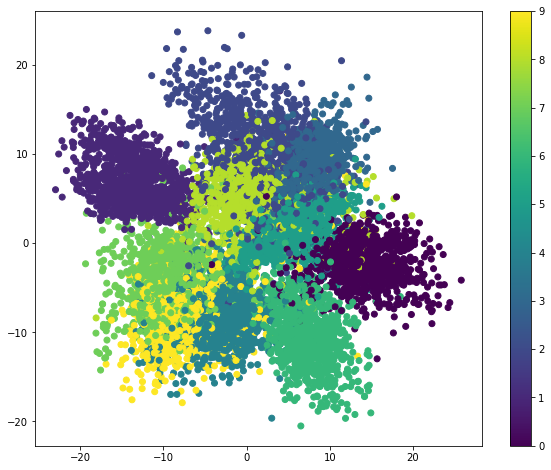
上面我以不同顏色當作不同的數字圖形,我們可以看到同樣的數字圖形會彼此聚成一團,所以的確同樣的數字的族群會被歸類到具有相似的特性,因此在code裏頭距離是彼此靠近的,還記得一開始我們沒加Regularization時。Model會把5看成是6,在這張圖你就會到原因,因為5號藍綠色和6號黃色靠的很近,很容易誤判。
這張圖同時揭露了Autoencoder的一個強大特性,注意喔!我們一開始Train這個Autoencoder的時候是沒有給它看任何Labels的,但他卻可以在壓縮資訊的同時找出規律,這個規律可以想成是我們人類在辨認每個不同數字的方法,所以Autoencoder可以在沒有Labels的情況下做歸納和學習,因此Autoencoder常常會被用在Unsupervised Learning (非監督式學習)。
另外介紹一種也是很流行的方法叫做t-SNE (讀作"tee-snee") ,這裡不多著墨這個方法的原理,但是它卻是目前2D Visualization最流行的作法,PCA只用線性的方式去做座標轉換,也就是從一個橫切面去看數據,這樣粗略的轉換並不能讓我們在視覺化時看出資料和資料間彼此的距離,尤其是從高維度轉換過來,經常會失真,而t-SNE是針對數據和數據間的距離去做轉換,最後被攤成2維時正是顯示數據點的距離關係,更能描述群聚的現象。
來看看t-SNE做起來效果如何。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |

去雜訊(De-noise) Autoencoder
我們巧妙的利用一下Autoencoder,我們將原本Autoencoder的前面加了一道人工雜訊的流程,但是最終又要讓Autoencoder試著去還原出原來沒有加入雜訊的資訊,這麼一來我們將可以找到一個Autoencoder是可以自行消除雜訊的,把這個Denoising Autoencoder加到正常Neural Network的前面,那這個Neural Network就擁有了抑制雜訊的功用,所以可以當作一種Regularization的方法。
先將圖片加上雜訊。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |

圖片現在看起來非常的髒。
用這些髒圖片當作Input,正常圖當作Output的目標,我們就可以自然而然的Train出可以消除雜訊的Autoencoder。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | |

上面圖片第一排為原圖,第二排是加完雜訊後的結果,第三排是經過Autoencoder後的圖,傑克真的是太神奇啦!所有的雜訊都被消除掉了,特別注意,這裡我的Regularization下的特別重,原因是雜訊增多了,也更容易Overfitting,所以要下更多的Regularization才能抑制它。