Tesla AI Day 2022 筆記
Posted on October 15, 2022 in AI.ML. View: 1,404
原始影片:youtube
Tesla Bot: Optimus
Demo

上次 Tesla AI Day 預告的人形機器人 Optimus 終於亮相了,Musk 說開發這個機器主要是要幫助人類完成一些枯燥或危險的工作,為了達到這個目的,Optimus 的手指有特別設計,可以靈巧的完成人類的工作,Musk 強調說目前市面上大部分的機器人都缺乏大腦,而且售價昂貴,Optimus 未來售價將壓在2萬美元以下,並且預計在明年開始量產。

Optimus 目前已經可以完成一些基本動作。

Optimus 採用在自動駕駛上使用的視覺系統,含有語義分割的功能,所以在 Optimus 的眼中它可以認得出它自身的部分、地板、花圃、澆水器、等。

Hardware Architecture
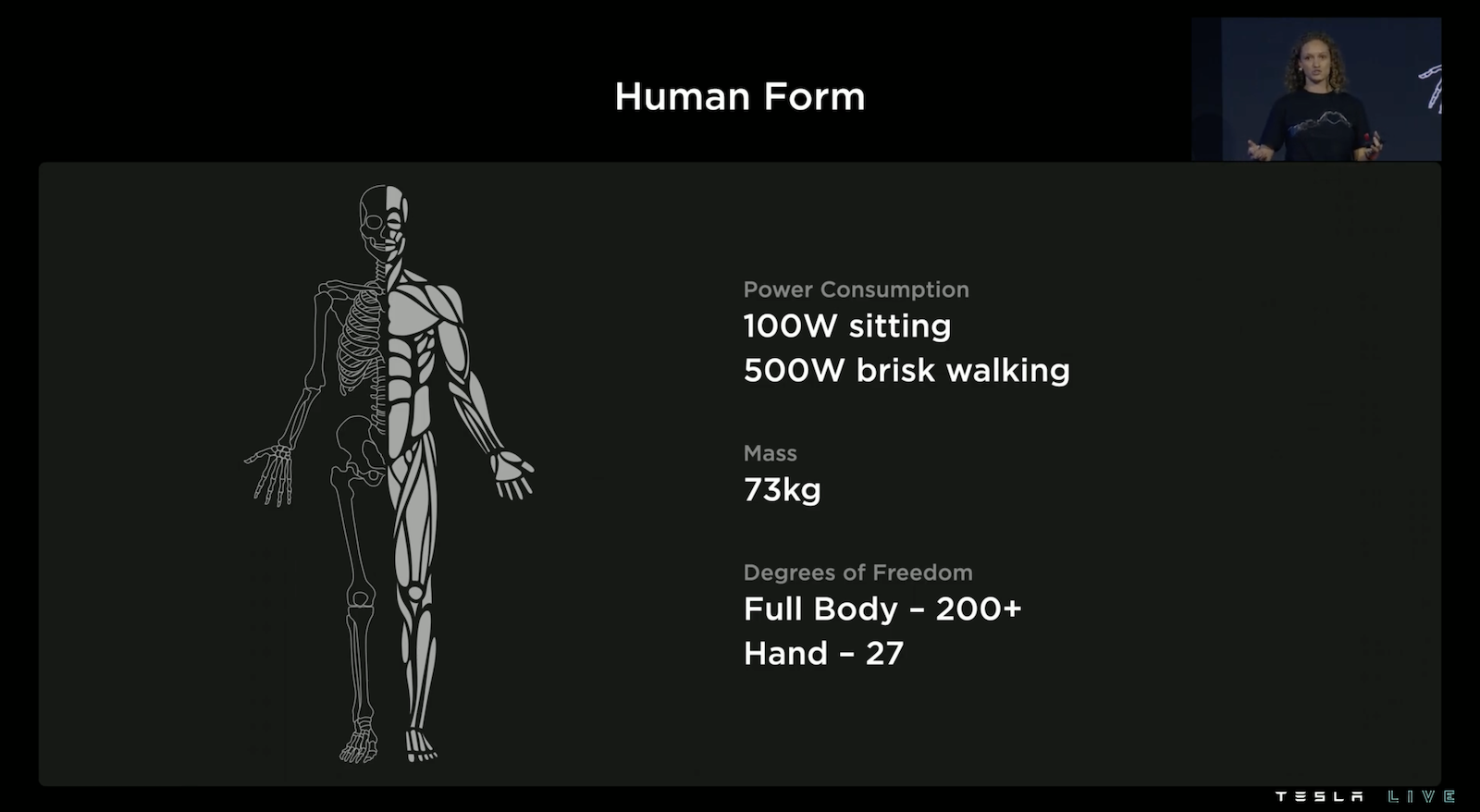
Optimus 以人的身體來打造,全身上下有多於200個自由度,自由度可以想像可以彎曲的地方,類比於人類的關節,而手有多達27個自由度,從影片仔細觀察 Optimus 的大拇指甚至可以向內折去碰觸小指頭,相當的細緻。而 Optimus 的重量也跟一個成人差不多約73公斤。並且 Tesla 團隊特別設計讓 Optimus 在待機的狀態下可以比較省電。

上圖橘色的部分為 Actuators(致動器,是一種將能源轉換成機械動能的裝置),而藍色的部分為電力系統,Optimus 同樣裝備著如電動車上的晶片,這晶片可以用來做影像處理、路線規劃,甚至他們希望未來我們可以跟 Optimus 溝通,所以裝備著無線連線器和聲音接收器。
Hardware Simulation
延續 Tesla 造車的經驗,Tesla 透過物理引擎模擬來設計機械結構,舉例:利用物理引擎模擬電動車撞擊的狀況來安全的設計車體結構。同樣的,可以透過這個物理引擎來模擬 Optimus 跌倒的狀況,並且設計 Optimus 在各種跌倒狀態下能避免電池和電路板等重要地方嚴重損壞。

同樣的,可以利用物理引擎來模擬機器人走路的受力狀況,並且設計出好的結構來應付各類動作。物理引擎可以有效的節省實體試錯的時間。
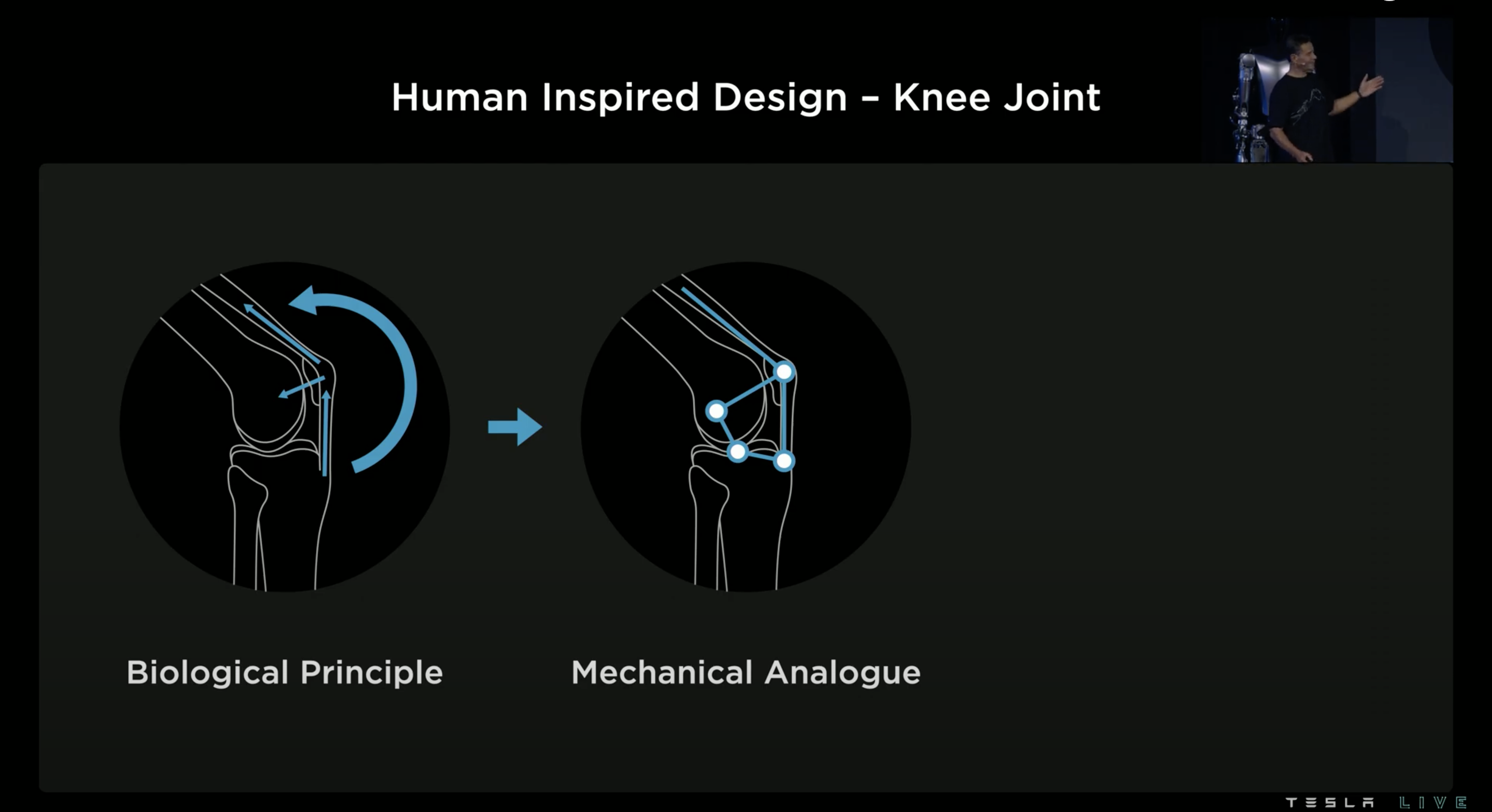
例如在設計膝關節也得益於物理引擎的幫忙,為了仿造膝蓋關節的結構 Tesla 經過模擬後採用「四軸系統」。
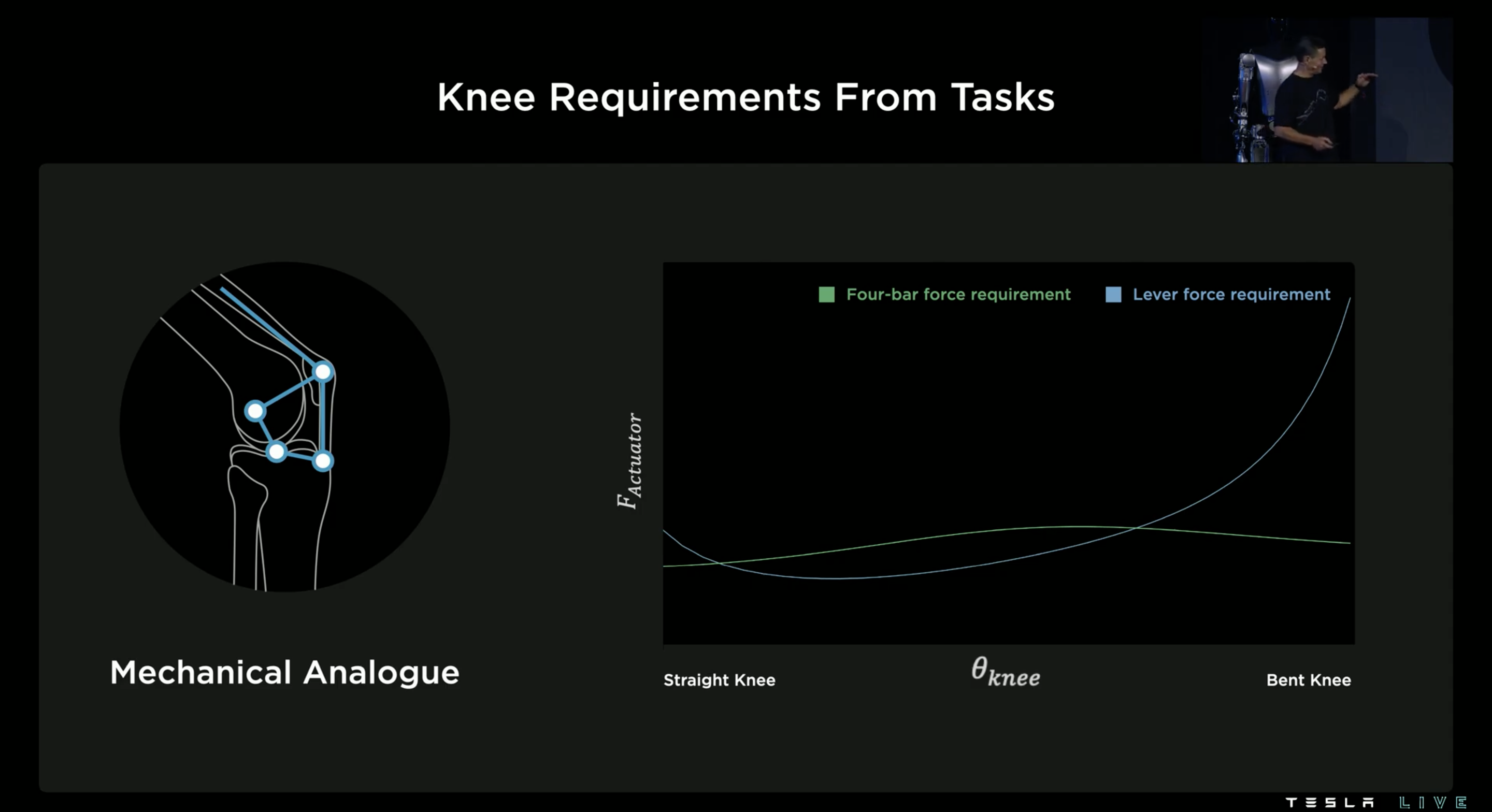
上圖綠色的曲線代表四軸系統,而藍色的曲線代表兩軸系統,其呈現的是在關節不同角度下的模擬受力狀況,可以發現兩軸系統在膝蓋彎曲的時候受力相當大,而四軸系統則能穩定維持低受力狀況,因此四軸系統比較有效率。
Actuators(致動器)& Hand

由電驅動的致動器已經用於電動車上,但電動車只需要前後兩個致動器,而為了支援人形機器人的各類動作,例如:走路、跑步、搬重物、爬樓梯等,Optimus 需要使用到28個致動器。
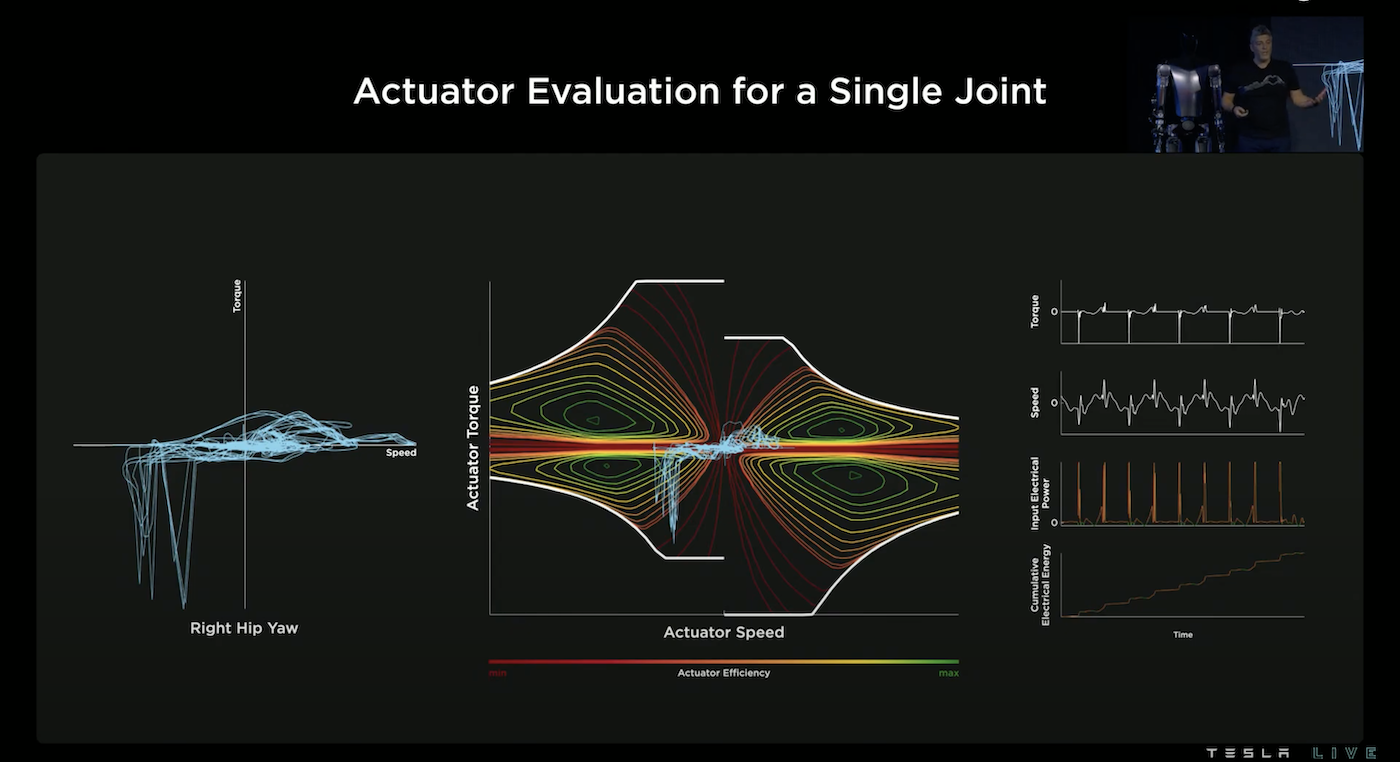
為了要選擇和設計這28個致動器,透過讓機器人走路和轉彎模擬並畫出各致動器的力矩-速度的軌跡,有了這個軌跡圖我們就可以計算某個致動器的耗能狀況,進而推算出其系統成本。
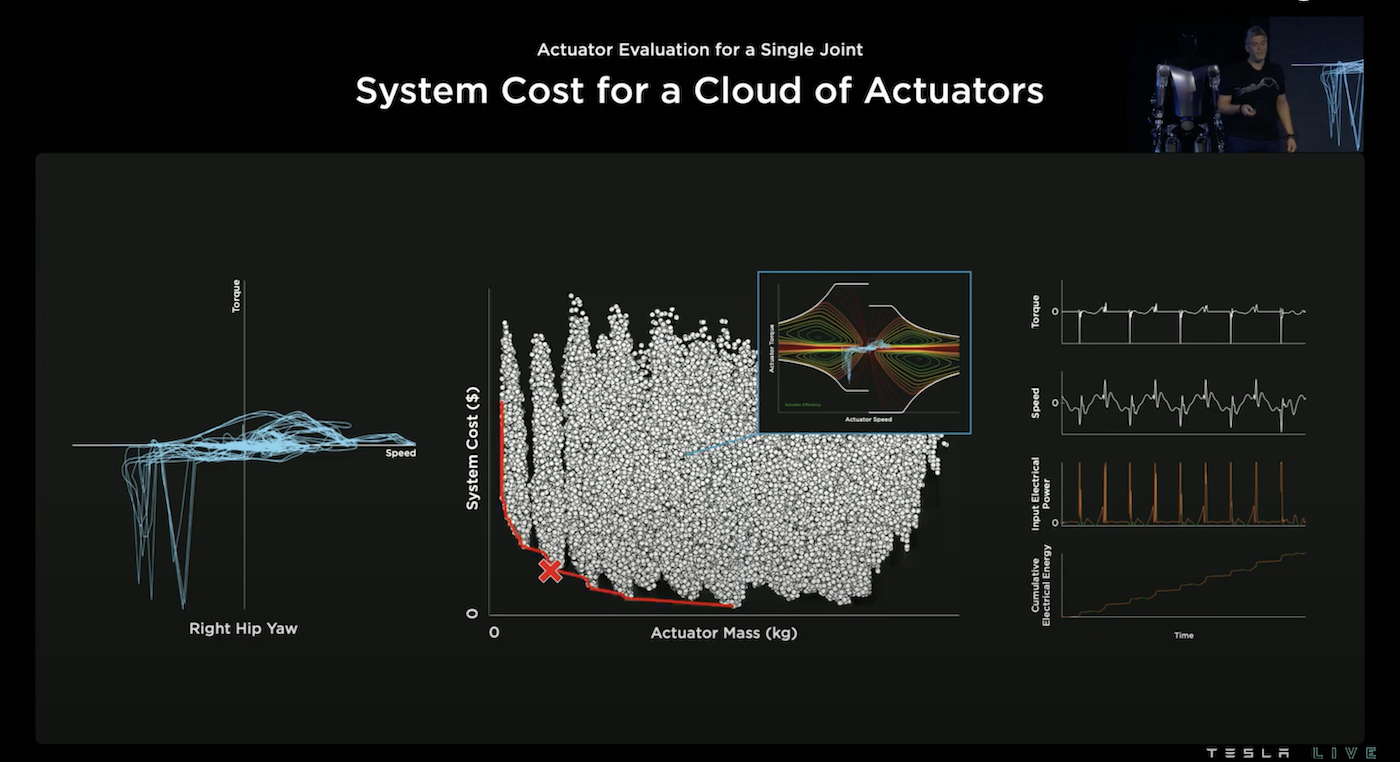
針對某一個位置,Tesla 團隊模擬了好幾十萬顆致動器並得到所有致動器在系統成本-致動器重量的分布,我們想要選擇系統成本越低、重量越輕的致動器,所以會選擇最靠近左下角原點的致動器,透過 Pareto Front 我們可以找出那最佳的致動器。
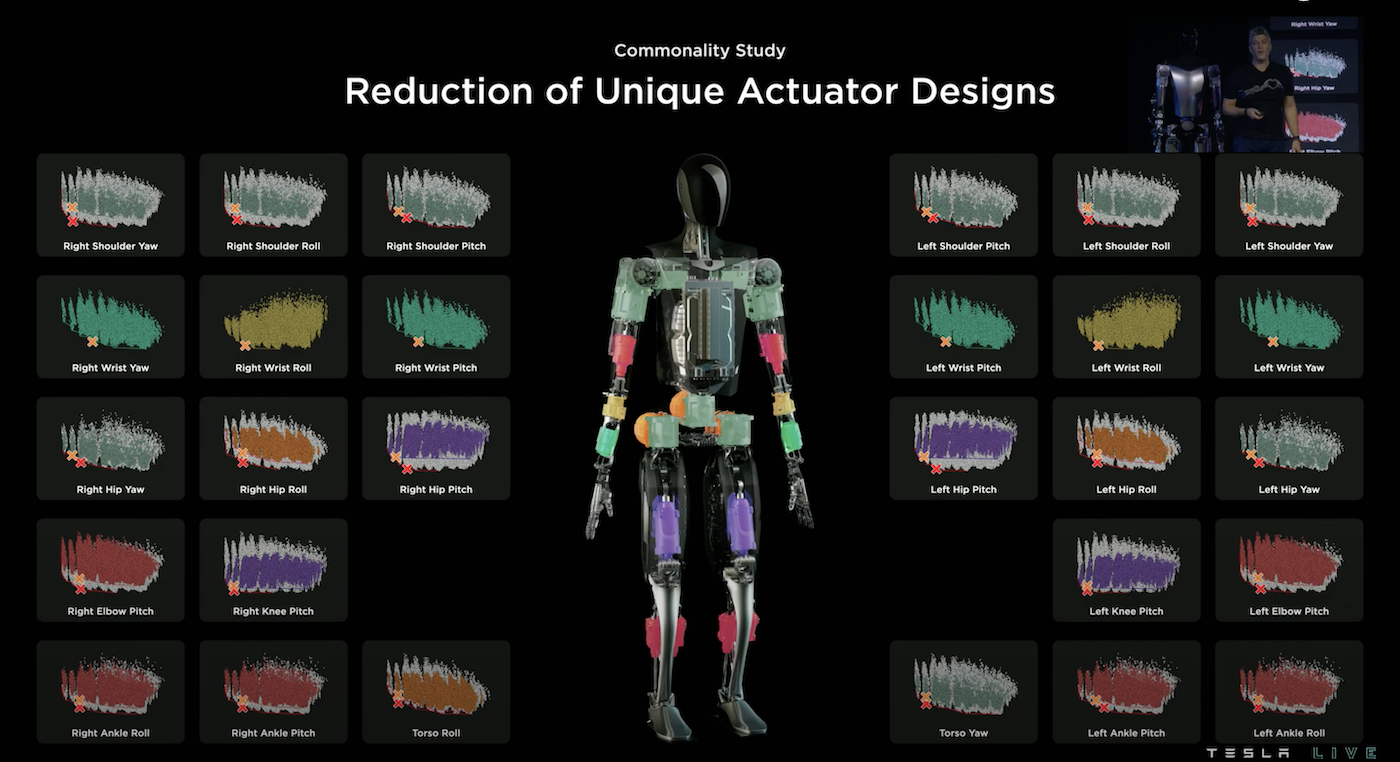
在28個位置都可以做同樣的計算,因此我們得到28種最佳的致動器,但是考慮到未來量產,28種款式顯然太多了,縱使因為左右對稱,可以省一半,但仍然還是太多款式,因此 Tesla 團隊透過 Commonality Study(共性研究)在權衡之下,使用6種致動器裝配在這28個地方。

這6種致動器如上圖所示,上排為旋轉式、下排為線性式。而講者特別展示他們的致動器有能力舉起一架三腳鋼琴,這並不是花俏的功能,這是必須要有的,因為人類的某些肌肉也同樣有此張力。

為了要打造像人類一樣靈巧的雙手,Optimus 手部使用了6個致動器,並提供了11個自由度。擁有可調整的抓握能力,可以依照情境去調整抓握的方法與力氣,可以提取約9公斤的重物,並且使用工具,甚至是相當小的物件。而特別有趣的一點是,Optimus 的手有嵌入 Sensors,所以在抓握的時候 Optimus 可以了解它與物件接觸的狀況來調整抓握的方法。
Optimus Software

Optimus 的視覺系統採用和自駕車相同的 Occupancy Network(詳見下方介紹),而因為通常在室內,所以沒有GPS可以參考,因此 Optimus 更仰賴於視覺系統。
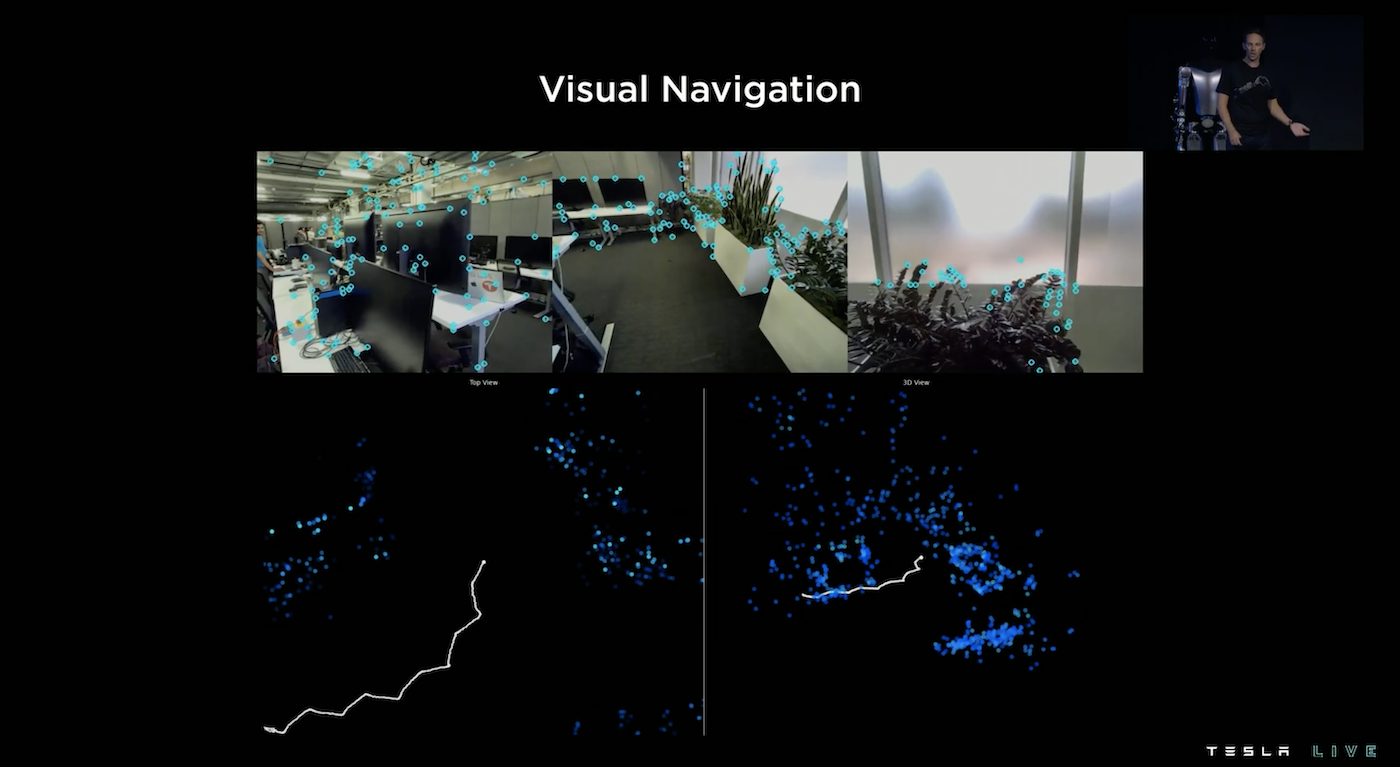
為了能在室內行走而不去撞到東西,Optimus 建基在 Occupancy Network 上預測圖上藍色的高頻關注點,可以控制避免 Optimus 去撞上這些點的同時,也可以可以利用這些點的實時變化來了解機器人自身的動作。
讓機器人走路並不是件容易的事情,要考慮以下幾件事:
- 對物理自身的了解:譬如腳的長度、重量、腳掌的長度
- 怎樣的走路姿態是節能的
- 平衡
- 協同動作
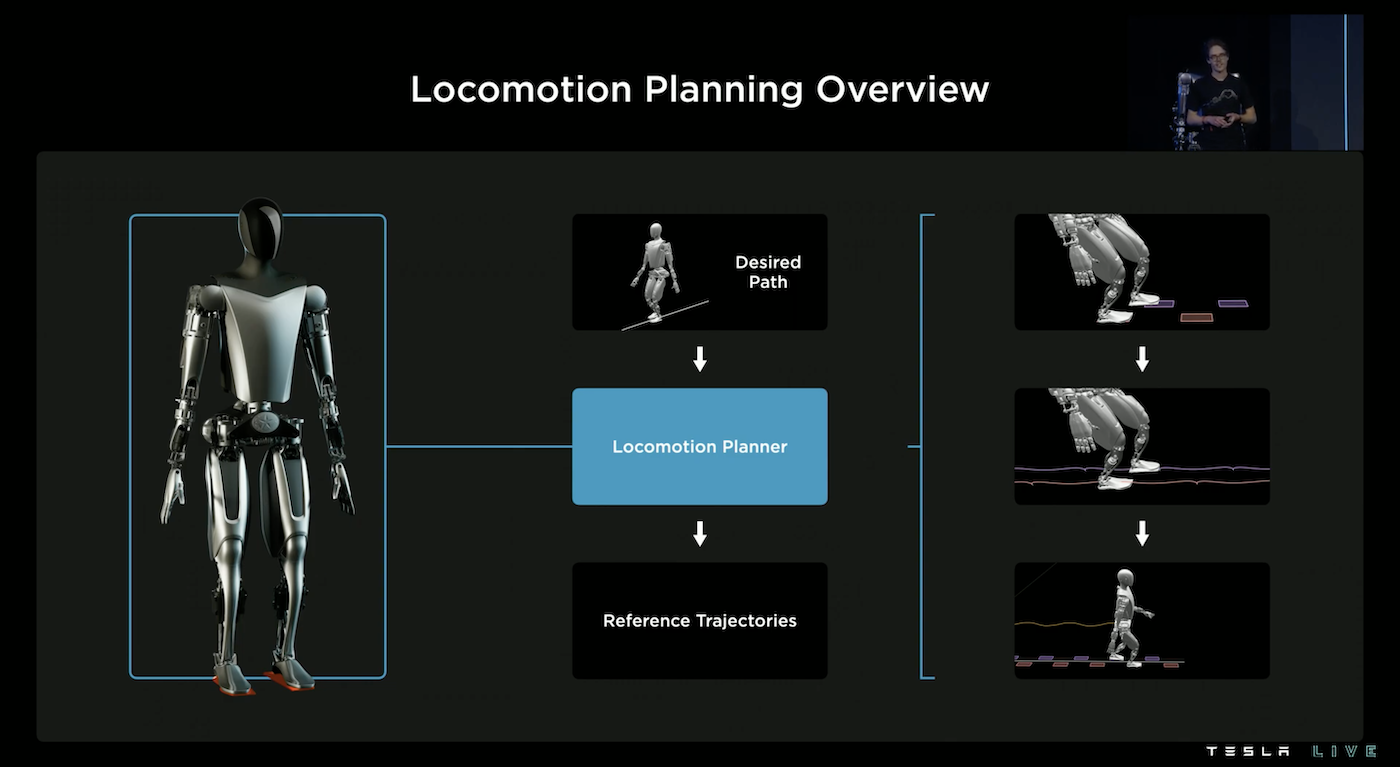
為了考量這些,Tesla 的作法是利用模擬去訂定移動計畫,並且規劃出軌跡,包括:左腳掌和右腳掌要踏的位置、腳掌的移動軌跡、骨盆的移動軌跡、等等。

但縱使使用模擬周全考慮後,在真實世界還是存在著誤差,例如:機器人可能會振動偏移、Sensors 也存在著觀測誤差,所以有許多狀況是超出模擬之外的,這導致一開始機器人是不穩定的,很容易跌倒。

所以 Tesla 提出了修正,建基在模擬預測之上,Optimus 使用 Sensors 去估計當下狀態,計算當下狀態與理想值的差異,並進行實時調整,才終於讓 Optimus 可以在正常世界行走。

為了要讓 Optimus 可以做許多人類的操作,Tesla 團隊蒐集了許多由人類示範的操作動作紀錄,把它們存成一個 Library。
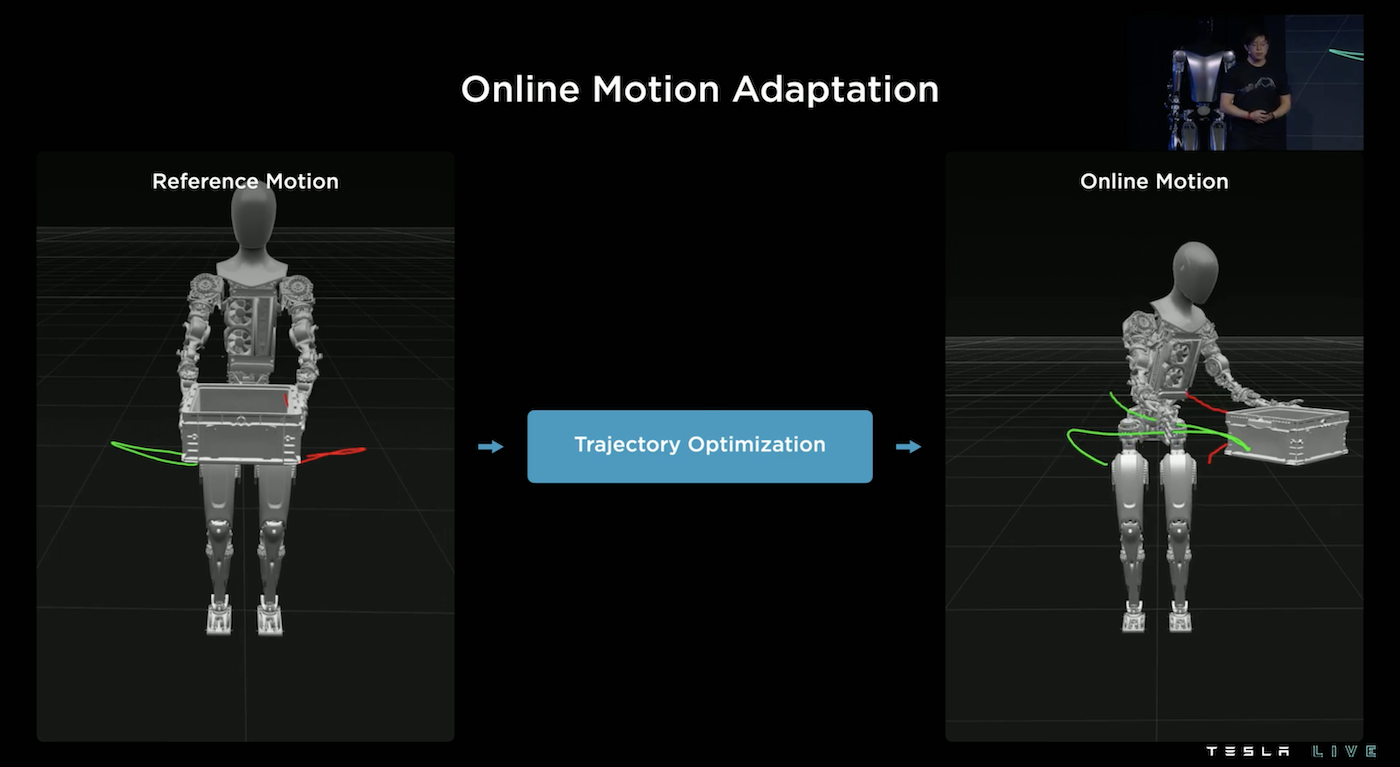
而就算是拿箱子的這一個動作有存在 Library 中,但是實際狀況箱子可能有大有小、有輕有重,也可能如上圖所示放在不同的地方、高度,所以我們不能直接使用 Library 中的示範動作,因此需要透過一個軌跡優化程式來調整雙手的軌跡,才能正確的完成任務。
Full Self Driving
Intro.
全自動駕駛從去年的2千個使用者,到今年2022已經提升到16萬個使用者,總共經歷了35個版本、訓練了近7.5萬個模型,大約每8分鐘就有一個新的模型。
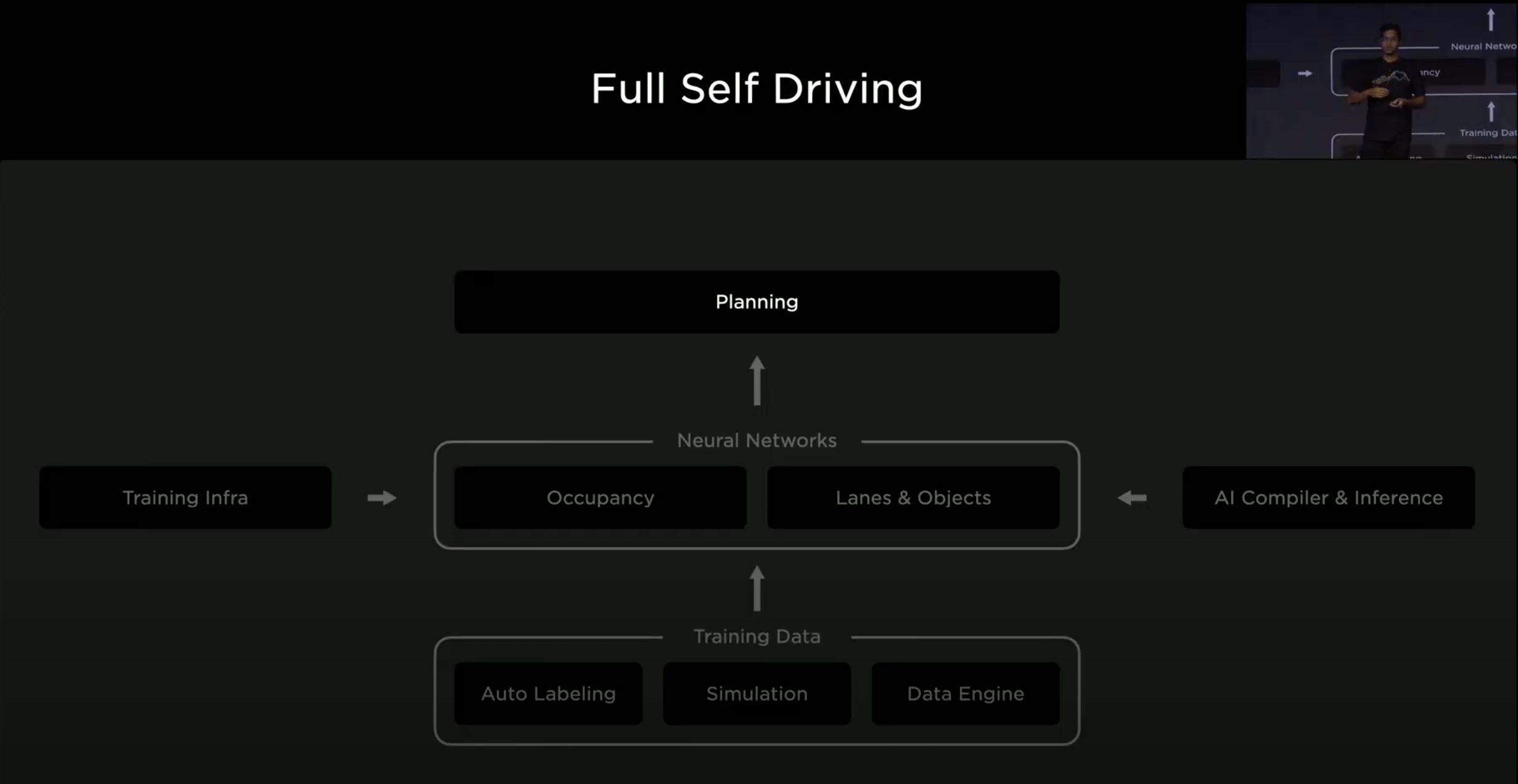
這是今天的大綱,Neural Networks 的部分包含了 Occupancy Networks 和 Lanes & Objects Networks,Occupancy Networks 作為底層描述幾何關係的預測,目標是從影像資料轉成實體世界,可以預測樹、牆、建築物、車,甚至預測它未來的移動方向;除此之外,Lanes & Objects Networks 提供了更詳細的語義預測。Training Data 的部分有去年提過的 Auto Labeling 和 Simulation,Data Engine 的部分則是描述他們針對錯誤的預測做改正的系統性作法。Planning 則是自動駕駛計畫它軌跡的程式。
Planning

計畫行車軌跡是相當複雜的,其需要考慮交互關係,如上圖,紅色的車輛想要左轉,卻遇到左前方的行人和右前方疾駛的車輛,它應該怎麼行駛呢?當下急轉顯然不是一個好行為,可能會撞到行人,所以人類駕駛會選擇讓行人先通過,再左轉從行人後方通過,但如果選擇這樣的路徑,右方疾駛的車輛可能會撞上,所以更好的作法是等待行人通過以及等待右側車輛通過再左轉。所以好的自動駕駛應該要能考慮接下來路徑的所有交互作用,但是這一切計算只能在50ms內完成,如果有大約20個物件要考慮,大概需要考慮100種的交互作用,要如何在這麼短的時間內將一切都考慮進去呢?Tesla 採用平行計算的樹搜尋法。
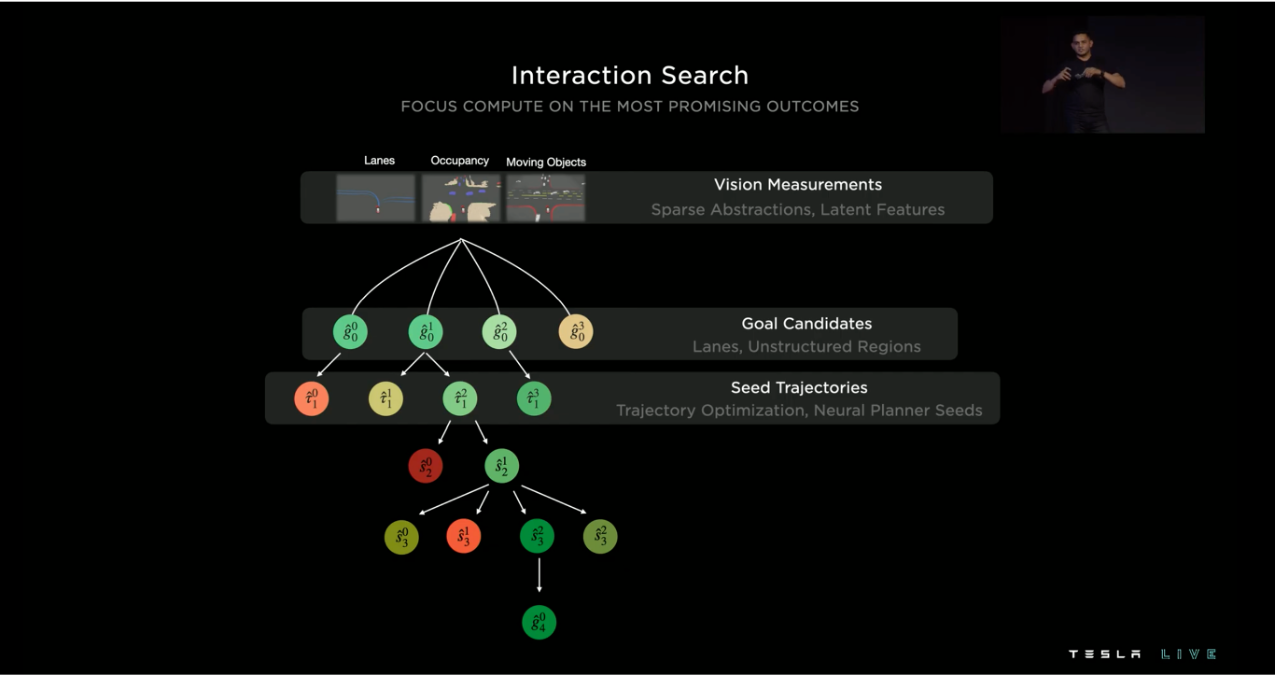

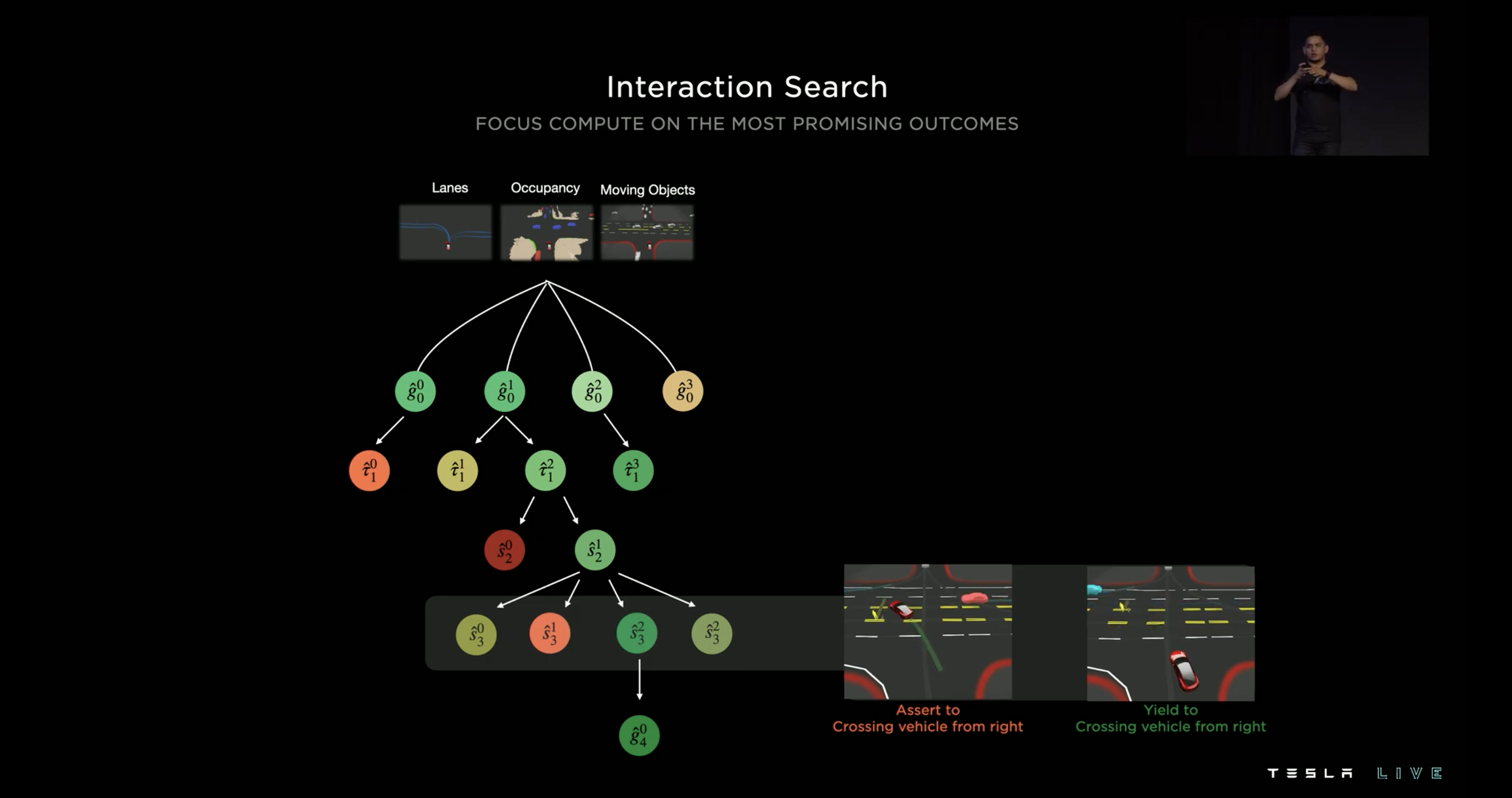
基於預測的 3D Vector Space,可以計算出多條可能的路徑,針對每一種路徑 Tesla 會逐一的檢查所有可能的交互作用,最後挑選出最佳的路徑,這個過程可以看作一個 Tree Search,並且可以採用平行運算來加速這整個過程。
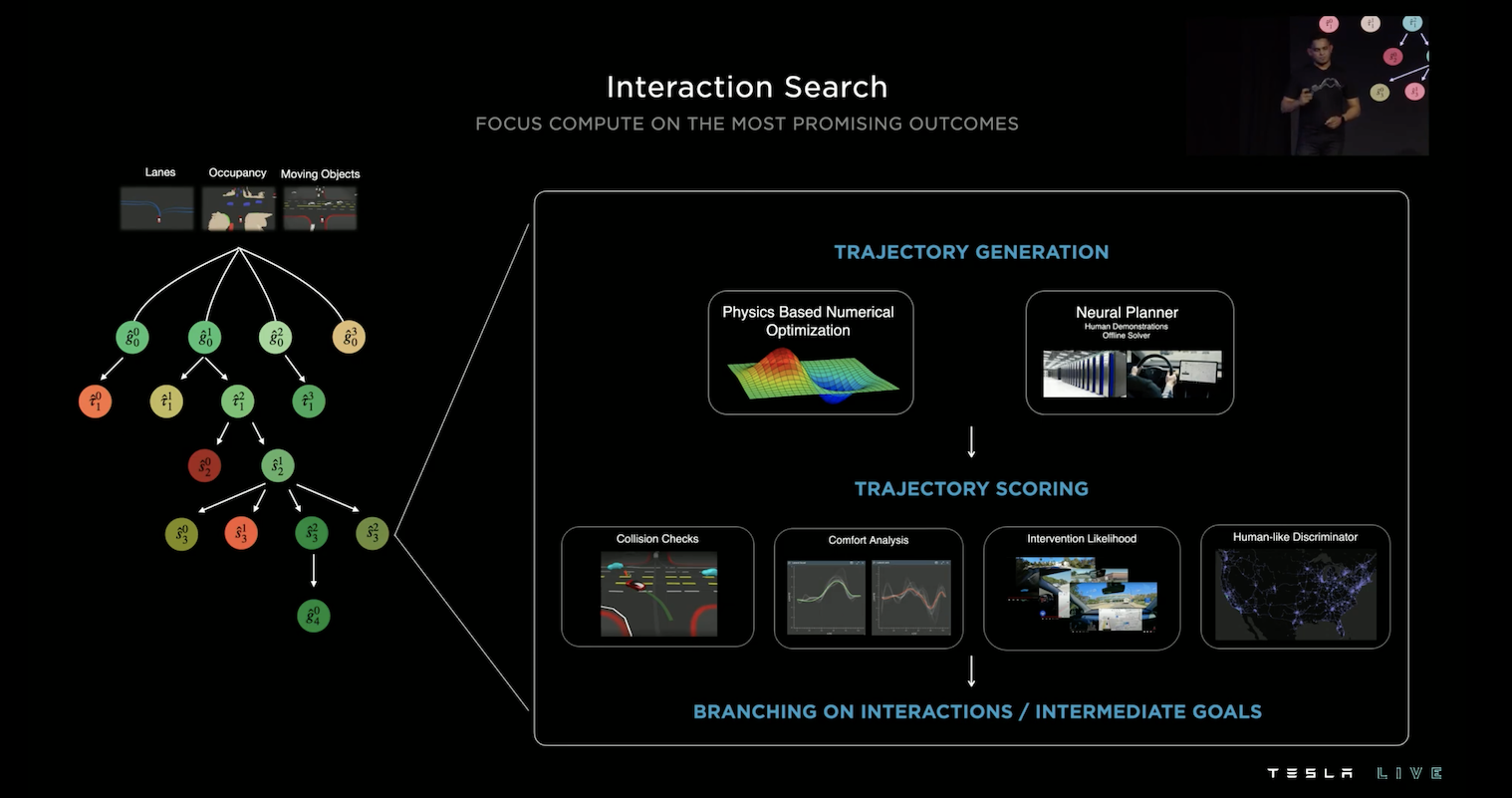
在樹中的每一個節點都會經歷三個歷程:路徑生成、路徑評分、基於交互作用或中間目標的分岔。
路徑生成的部分,他們曾經嘗試使用物理數值優化,但這過程太過緩慢,平均一個動作需要花費1-5ms,如果有100個動作則最少需花費100ms,這超出了我們的限制,所以他們接著考慮使用神經網路的方法,讓神經網路學習人類的操作示範或數值優化後的路徑,如此一來便可以將一個動作壓在約100us,成功的解決問題。
路徑生成過後,他們會針對路徑作評分,會考慮剛剛提到的「可能撞擊檢查」,好的路徑要禮讓行人、避免與其他車輛擦撞,同時也考慮了「行車舒適度」,並且使用神經網路的方法去評估「車主取消自動駕駛接管的可能性」和「這路徑像不像人類的行駛方法」。
Occupancy Network
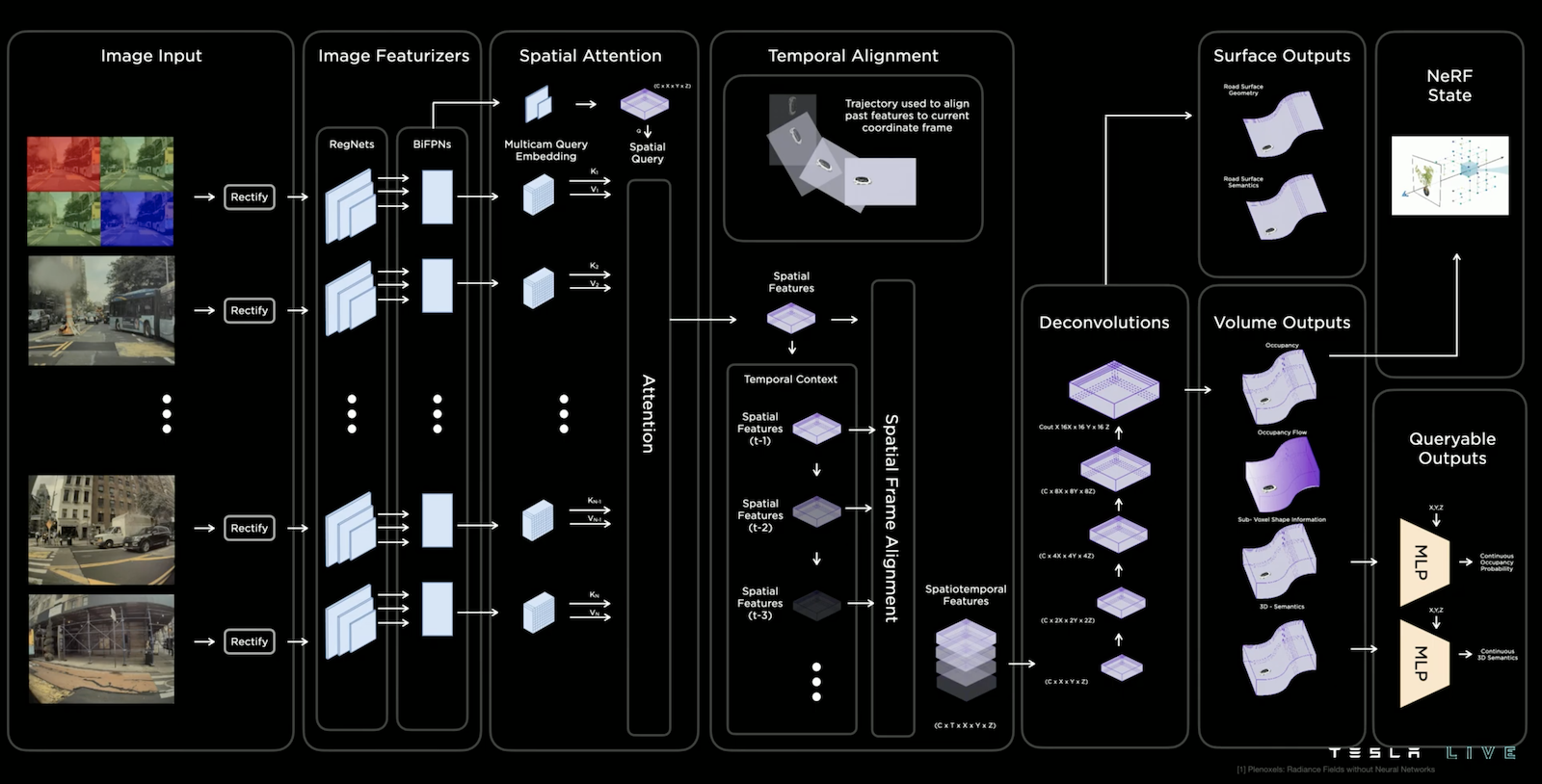
Occupancy Network 作為底層描述幾何關係的預測,目標是從8顆鏡頭影像資料轉成實體世界,並提供所需的語義。它有以下特色:
- 能描述 Volumetric Occupancy (體積佔用)
- 考慮了多鏡頭、影片的上下文
- 能穩定的預測物件,不容易出現物件跳躍的情況
- 同時能預測物件的語義
- 同時能預測物件的動向
- 有效率的記憶體使用和計算能力
- ~10ms 的更新率
而上圖為其結構,其實跟去年相去不遠,可以說是將去年提及的 HydraNets 和類似 NeRF 描述 Voxels (可以想成在3D中的Pixels) 的技術相結合,去年提及的部分就不贅述了(請詳見 Tesla AI Day 2021 筆記),讓我們專注的討論今年值得一提的更新或更詳細的內容,如下:
- 在 Deconvolutions 後,會進行 Volume Outputs 和 Surface Outputs 的預測,除了預測幾何關係外,還會預測語義和動向
- 為了增加預測的解析度,他們設計了 Queryable Outputs 將原本 Volume Outputs 的資訊壓入 MLP 中,接著就可以查詢這個 MLP 來得到解析度更高的資訊,你可以想像在這個過程模型考量了許多資訊後給出了良好的內插結果,所以可以得到更高解析度的資訊
- 同時,他們也使用類似 NeRF 的方法來描述 Voxels,今年他們給出了相關的論文— Plenoxels: Radiance Fields without Neural Networks, Alex Yu et al., 2022,這個技術不需要神經網路也能訓練 NeRF,並且在品質些微提升的情況下降低了時間複雜度兩個數量級
Training Infra.
為了要應付龐大的計算量,Tesla 裝備著14K顆GPU,其中4K顆作 Auto Labeling 之用、10K顆作模型訓練之用;並且裝備著30PB的分散式影片快取記憶體。

但是並不是將大量的GPU和大容量的記憶體裝上去就完事了,Tesla 團隊還為底層做了很多的優化,如上圖所示,例如,擴充原本的 PyTorch 加速影片訓練速度、設計新的儲存格式 .smol 來降低容量和減少輸出寫入的操作次數。在優化過後,訓練 Occupancy Network 的速度提升了2.3倍。
Lanes

縱使我們已經使用 Occupancy Network 重建了整個實體世界,包括標線、車輛、紅綠燈,但行車的路線仍然不是顯而易見的,如上圖所示你可以了解行車路線有多麼複雜,它包含著行車方向、變換車道、道路切換,所以我們希望使用神經網路來預測所有可能的路線。
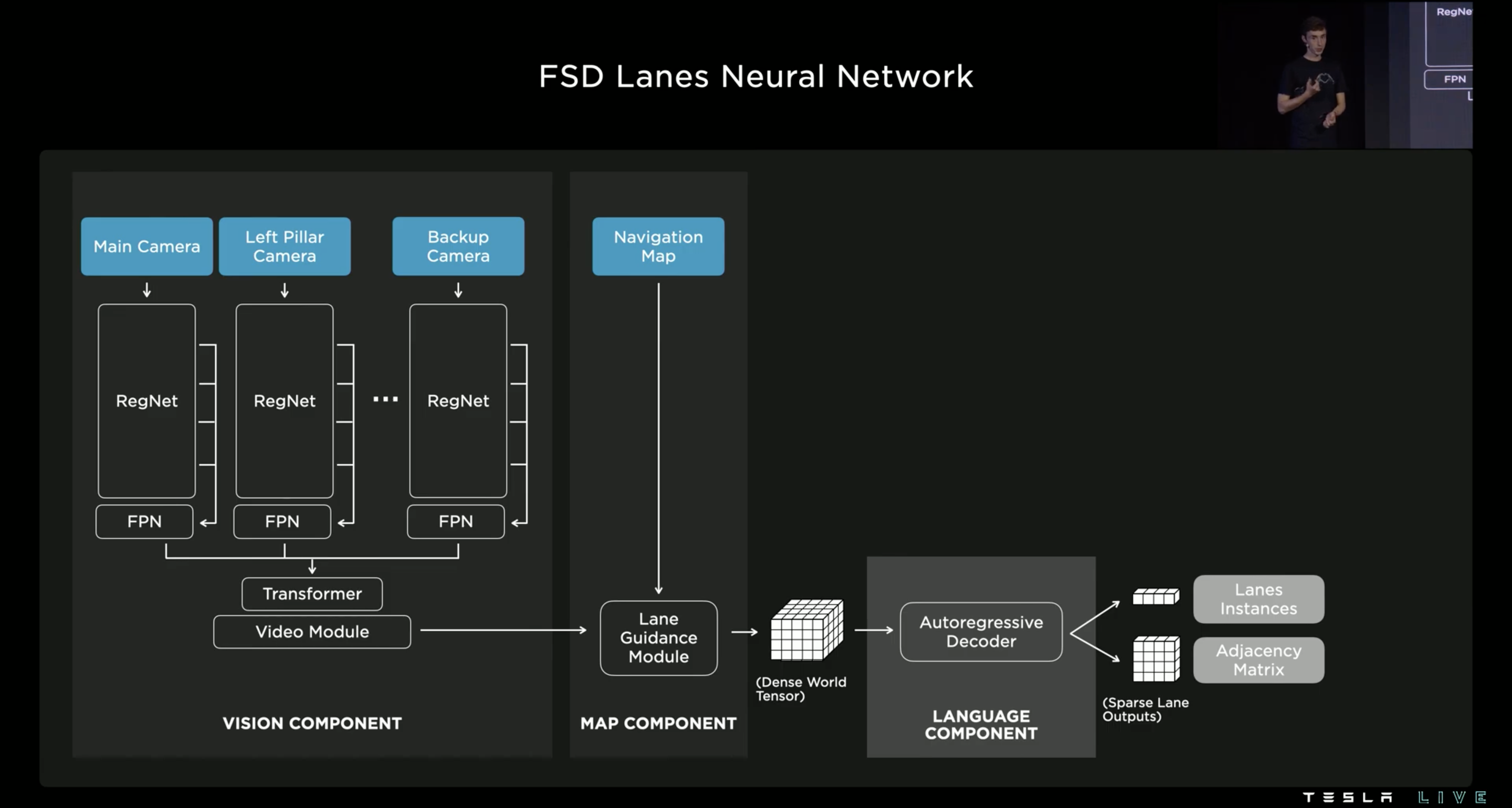
FSD Lanes Neural Network 分為三個部分,Vision Component 設計的如同 Occupancy Network 的 Backbone 一樣;Map Component 則是希望融入 Navigation Map 的資訊,包括:路的幾何和拓撲、行車方向、車道數量、車道的拓撲、是否為公車道、是否為高乘載車道、.. 等;Language Component 則是希望以稀疏的形式輸出所有可能的路線,這邊的作法是借鏡了語言生成(如:GPT3)的方法,將路線化作一種語言,希望模型在參考視覺之後以 Autoregression 的方式生成這個關於路線的語言,以下詳細說明。
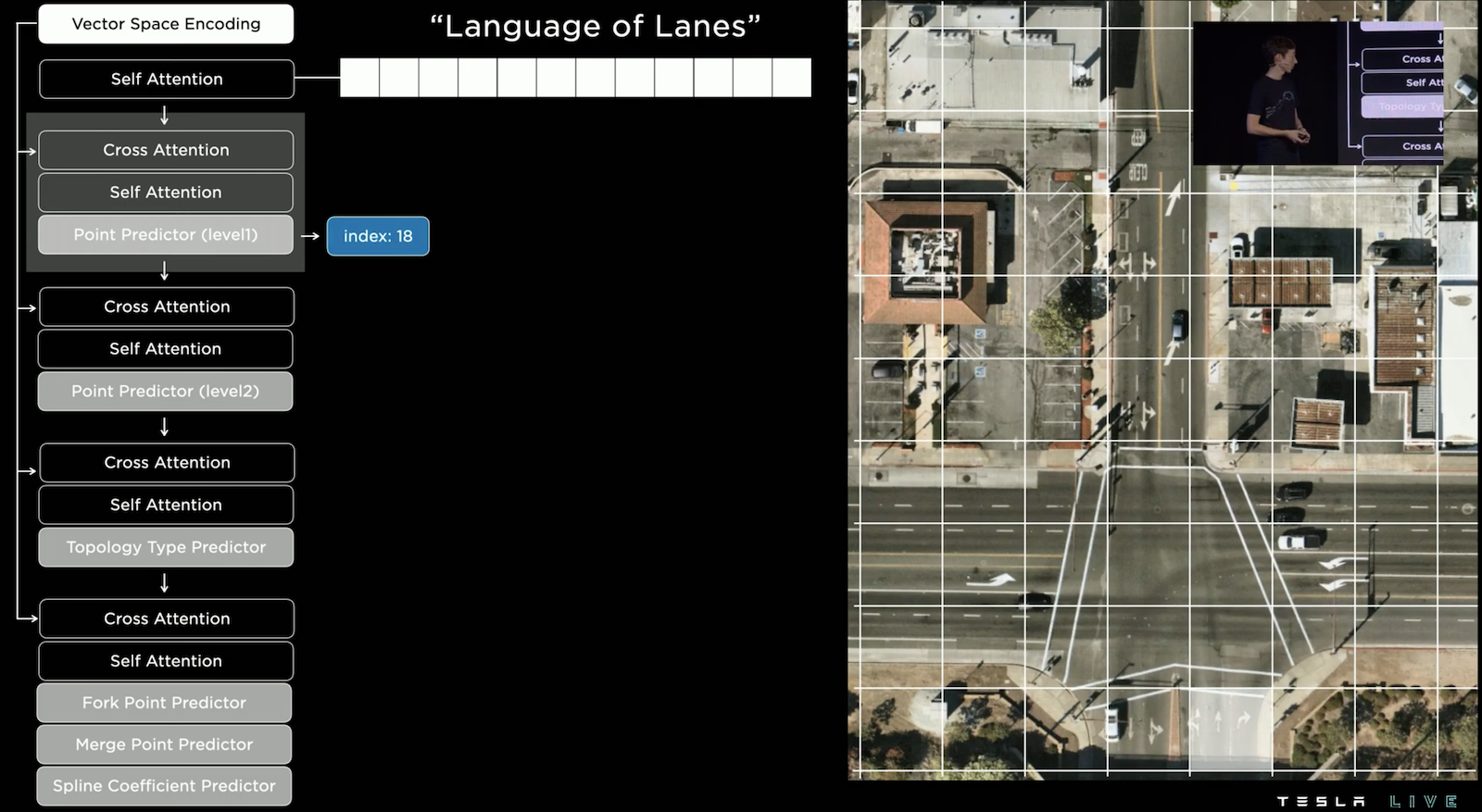
右側是鳥瞰圖,我們要在其上預測所有路徑,左側是 Autoregressive Decoder,這邊採用多層次的預測,要注意每一層的預測皆有使用 Cross Attention 參考影像及地圖的資訊。首先要預測節點位置,但因為計算量的考量,所以採用先在大的網格上預測位置,這次輸出是 index 18,我們可找到它並反白它的位置。
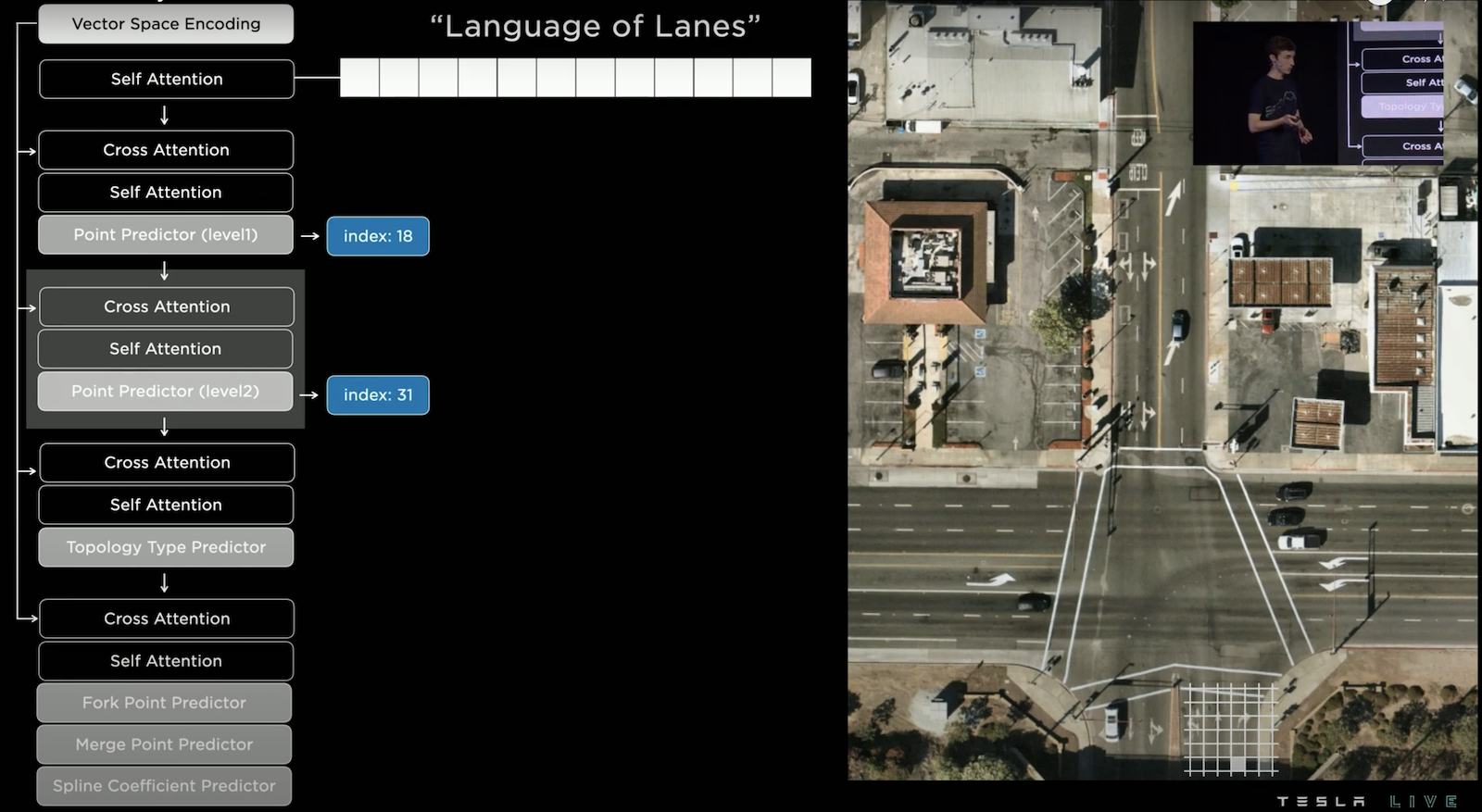
接下來接續著預測它細緻的位置,此時輸出index 31,我們可以找到它並反白,此時已經確認了點位。
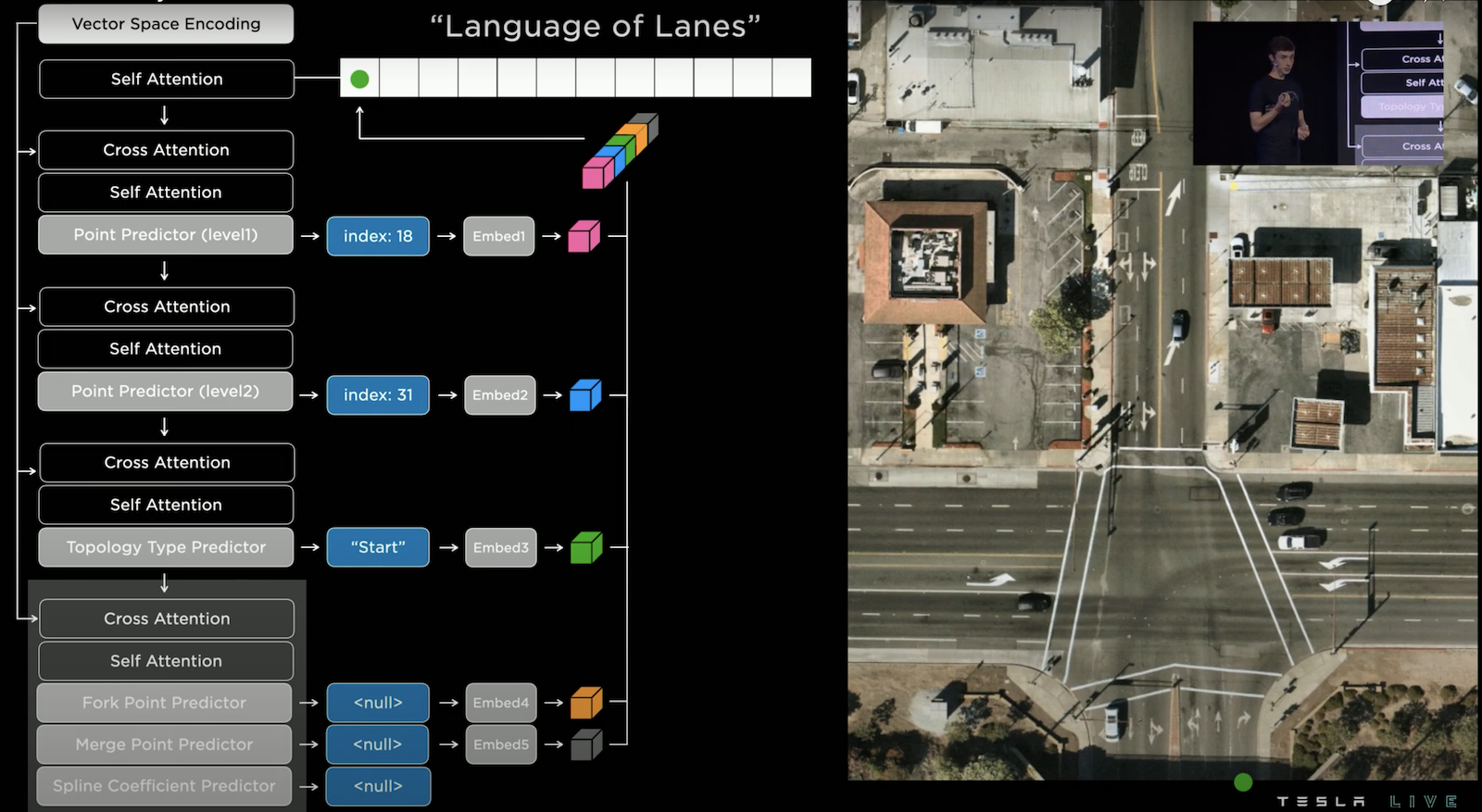
接著預測這個點的「拓撲類型」,這邊預測的是 "Start",也就是道路的起始點。我們可以將這些所有輸出組合成為一個 Character,然後接續的輸出下一個 Character 直到結束,是不是很像一種語言!
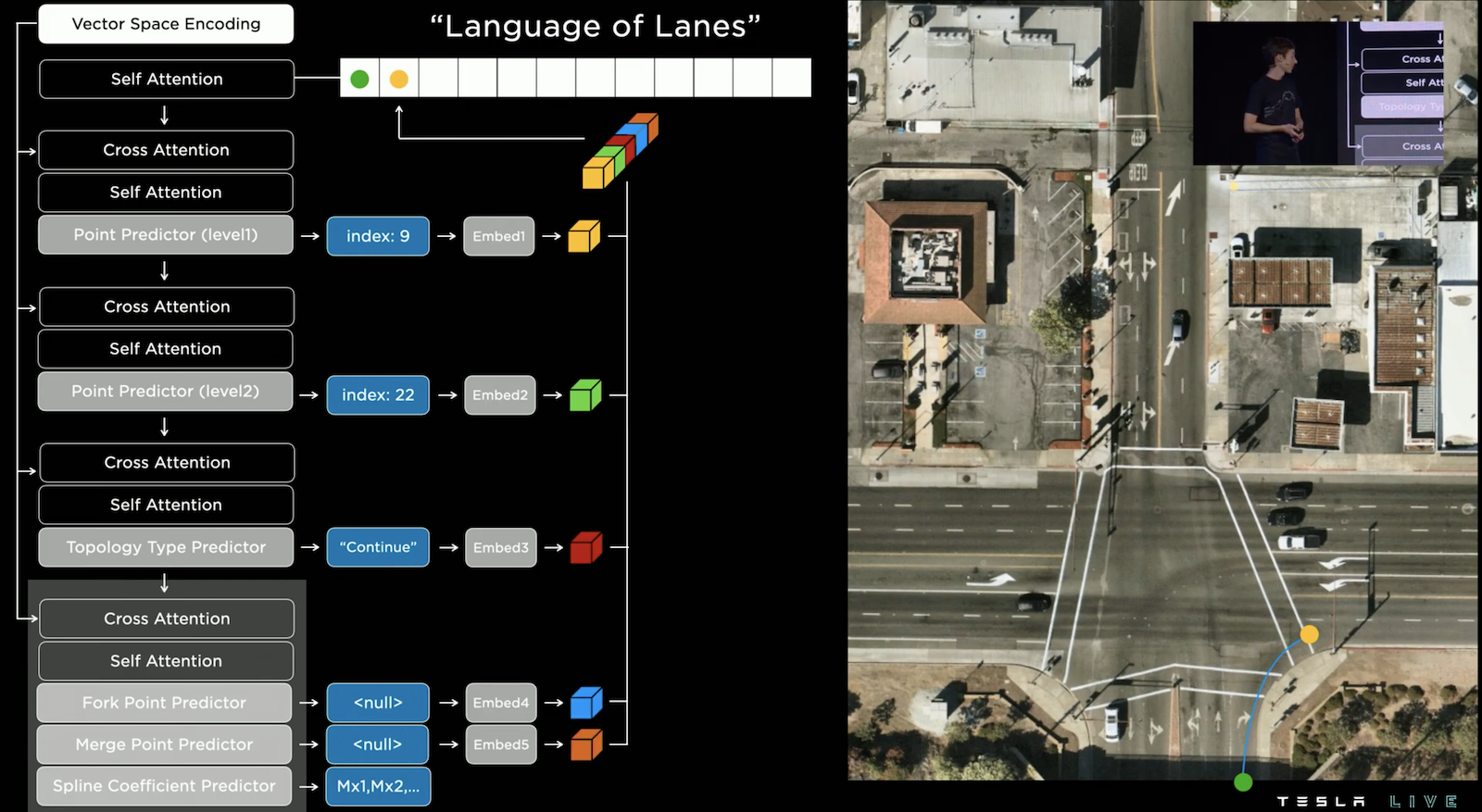
當我們接續的輸出下一個 Character,這次是輸出黃色的點位,其拓撲類型為 "Continue",這意味著與上一個點相連,而相連的軌跡則由 Spline Coefficient Predictor 預測,它會透過預測係數來描述兩點連接的平滑曲線的形狀,如此一來我們就使用語言的方式連出一條「路線」。
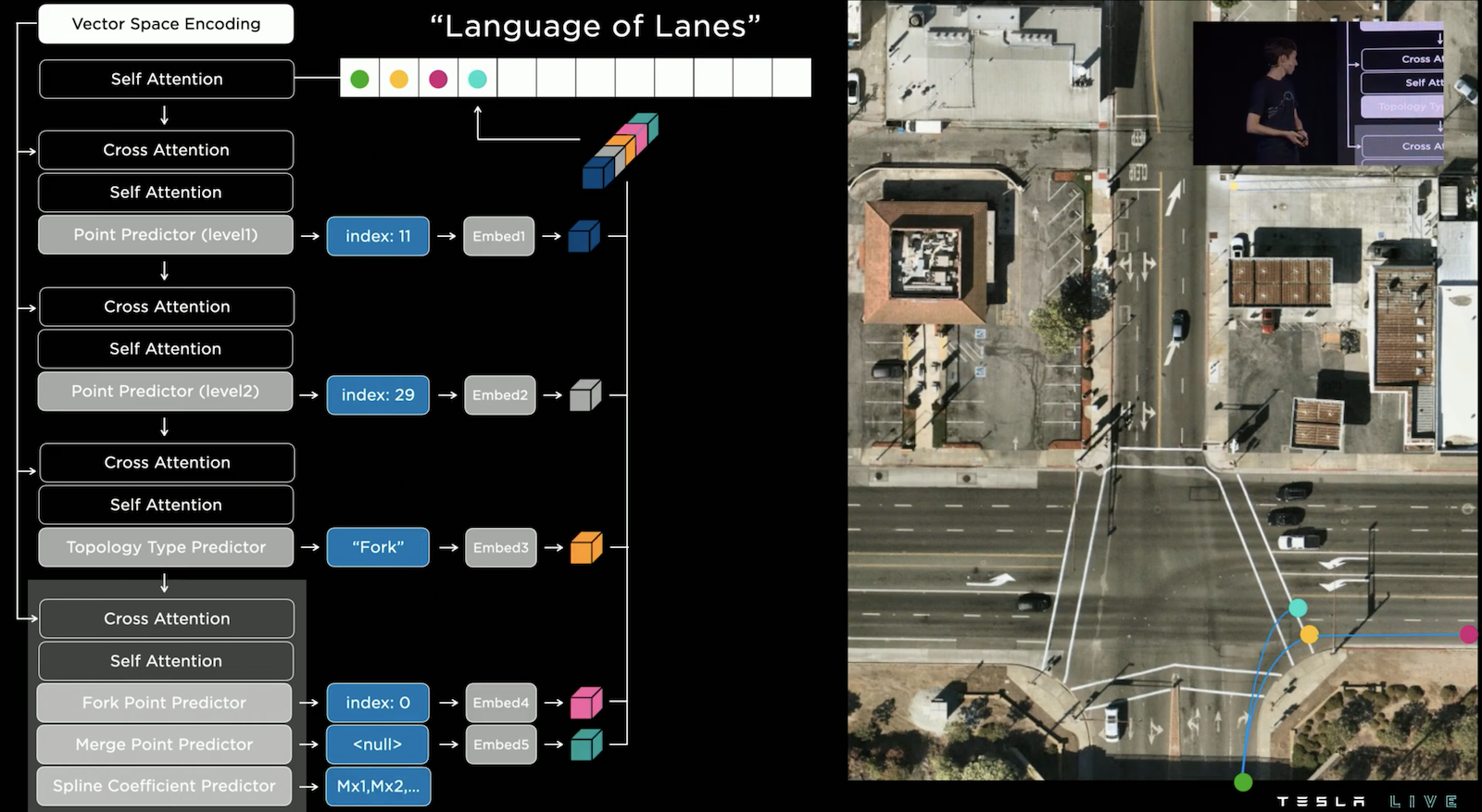
當然一個點可能有包含多條岔路,上面的例子預測藍綠色的點,其拓撲類型為 "Fork",而 Fork Point Predictor 預測 index 0,代表是從第0個位置的點分岔出來,而 Spline Coefficient Predictor 同樣的預測兩點連線的曲線。
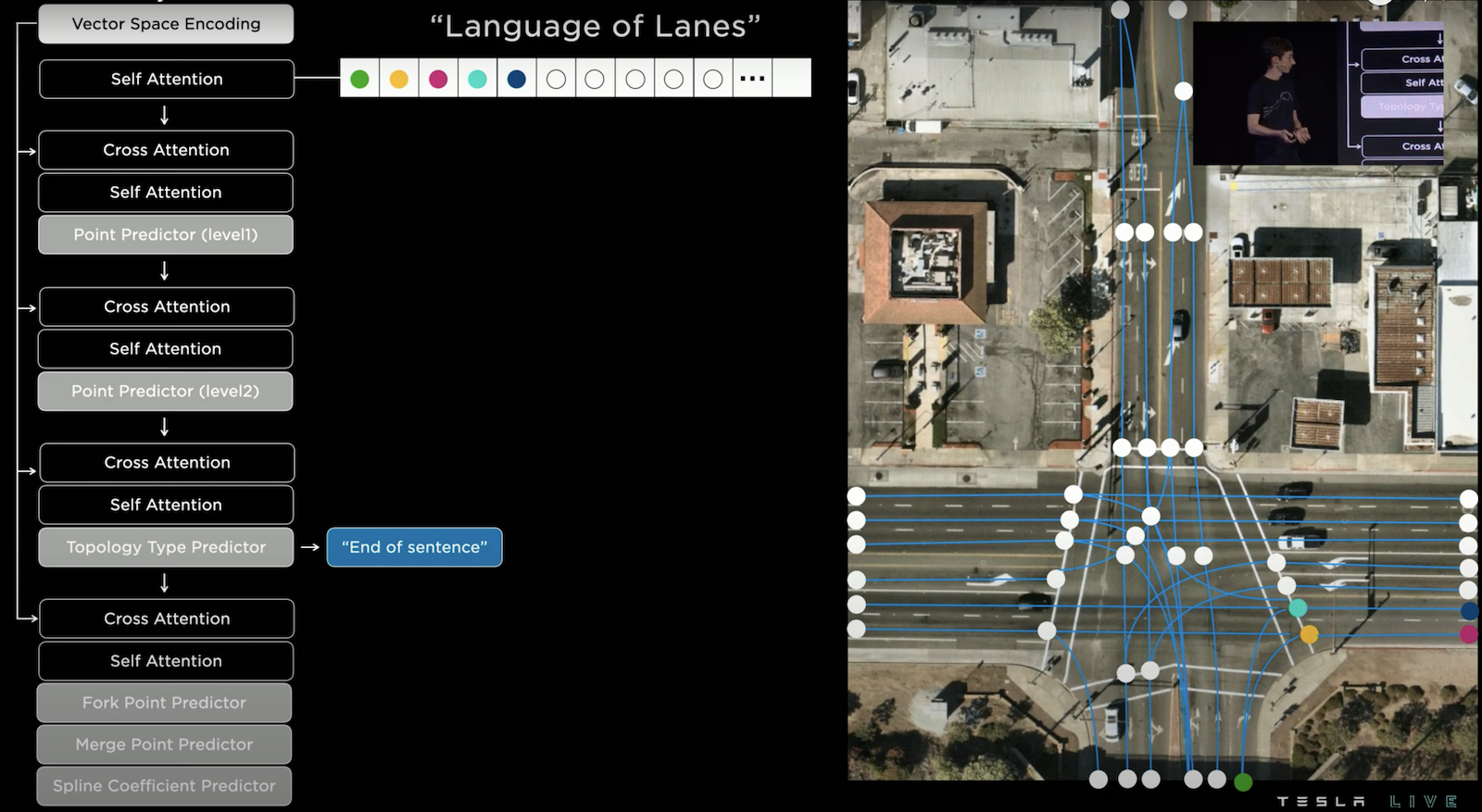
這個操作一路的進行下去,直到出現拓撲類型為 "End of sentence" 為止,我們就成功的建構了所有的路現,是不是很聰明的想法!順道一提這個技術同樣的用在機器人 Optimus 上。
Auto Labeling

在2018年 Tesla 還在 Image Space 上作標注,那時每一個 Clip 需要標注533小時。而目前使用的 multi-trip 版本每個 Clip 只需標注不到6分鐘,Auto Labeling 的技術帶來巨大的改變。其作法和去年的差不多(請詳見 Tesla AI Day 2021 筆記),他這邊特別強調三個步驟來達到這樣的效果:
- 高精度的軌跡:使用模型在每個軌跡上預測高精度的資訊,在目前任務中這個資訊就是指 Lanes
- 多旅程重建:因為一條路徑可能有多台 Tesla 電動車在不同時間不同天氣開過無數遍,所以可以將這些資訊疊加在一起去雜訊,建構出更穩固的 Label
- 運用於新路徑:當然 Auto Labeling 也可以運用在新的路徑的 Label 生成

當然還有一些時機 Auto Labeling 並不能表現的很好,例如:缺乏光線、濃霧、遮擋和雨天,還有待加強,不過不用擔心的是,因為在同一個路段會有不同時機的 Clip,所以縱使當下表現不好,也可以拿過去的資訊來彌補。
Simulation
- 可以亂數生成行車路徑,再基於此路徑生成路面、行道樹、建築、天空,並在合理的位置生成紅綠燈,並且創造車輛行駛在可能的路徑上,這一切只要幾分鐘就可以用模擬器自動生成
- 同一個場景,模擬器可以產生不同天氣、日光
- 甚至可以基於 Google 地圖去生成模擬城市
Data Engine
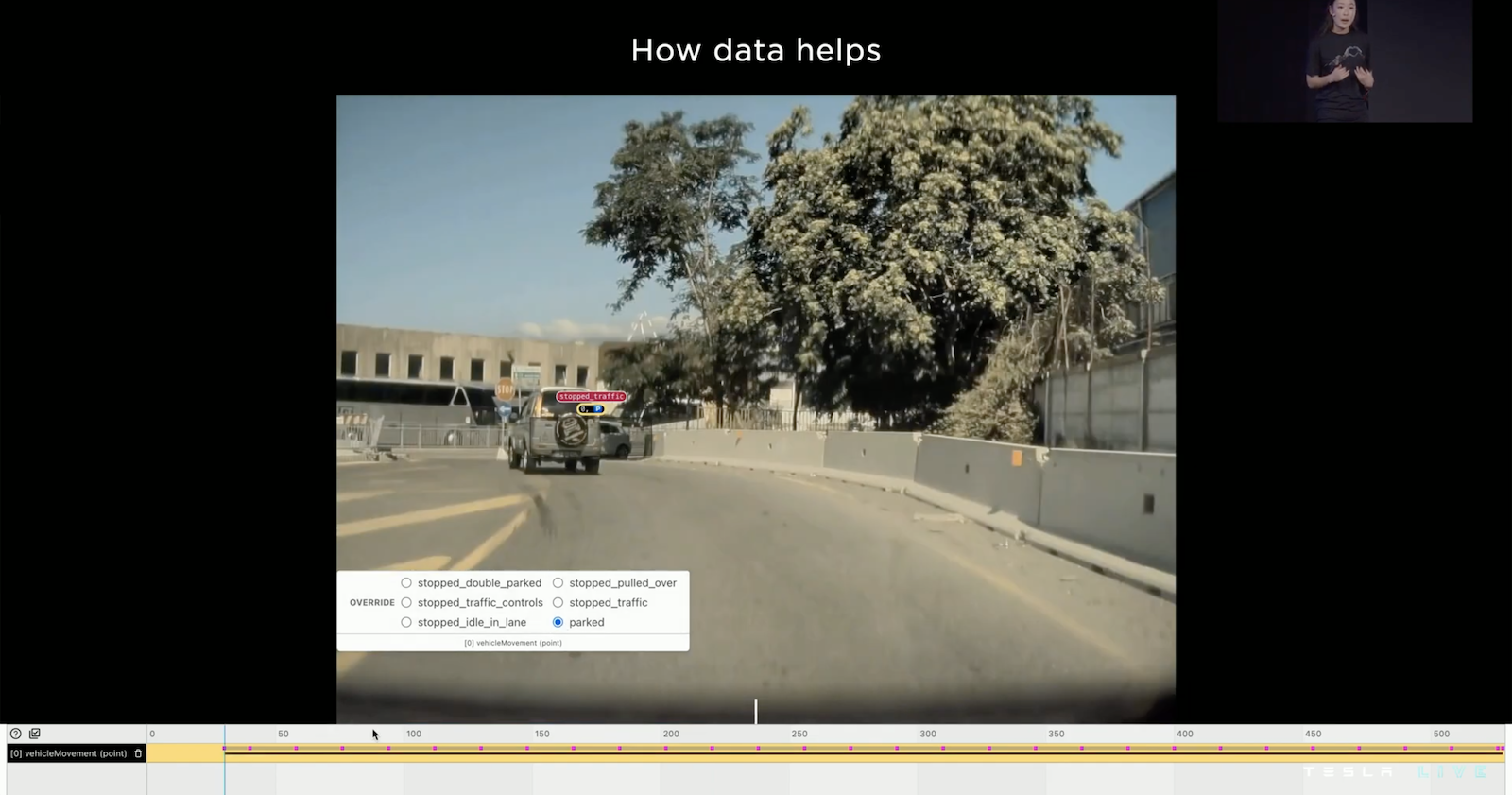
Tesla 建構一個標注的流程,讓標注人員針對模型預測錯誤的部分進行修正,並且將這些資料放到資料集當中。舉例,預測停車的問題,上圖中模型預測車子不處於停車的狀態,但標注人員從 Clip 看出車內沒有人,所以他手動標注為停車狀態,而這筆資料就相當有價值,會放進去讓模型重新訓練。和學術界不同,Tesla 不固定他的資料集,而是持續擴增他的資料集,為的就是確保在各種情況都能安全的駕駛。
我的觀點
- Tesla 花不到一年的時間打造了人形機器人 Optimus,雖然相比於 Boston Dynamics 的 Atlas 機器人來說,Optimus 像個小嬰兒一樣,但不到一年就有如此成果,個人覺得已經是相當快速了,要知道雙足行走是相當困難的。
- 我們從設計來看,Tesla 確實想要打造一台可為人類工作、低價、可量產的機器人。Optimus 具備純影像視覺系統,可以感知物件並了解其語義,並且仿造人類來設計機身,手部的靈活度也是少見於機器人的,因此這樣的機器人才有機會可以做到像人的動作,才有機會讓它來幫助人類完成一些枯燥或危險的工作。並且在設計初期,他們已經在考慮未來如何降低售價和量產了,我們看到他們如何利用模擬來找到低成本和低重量的致動器,我們看到他們使用共性研究將28種致動器降至6種。因此我是相當期待 Optimus 接下來的發展的!
- 個人認為如果想要打造可為人類工作的機器人還有一件很重要的事情,很可惜它沒在這場演講被提及和說明,那就是「互動介面」,例如我想要機器人幫我洗衣服,我可能必須指示它一些步驟,例如:把衣服從籃子拿出來、放到洗衣機、加入洗衣劑、等,但我怎麼告訴機器人。是想要透過語音輸入嗎?可是語言理解是個大坑,在語音和語言理解這塊,Tesla 在資料上和 Know-how 上並沒有優勢,所以也許要透過如此自然的方法互動還需要好幾年的時間開發。抑或是想要透過程式操作?為了要能靈活操作各類任務,這勢必要設計一種程式框架來描述這模糊的世界,並且這樣的框架還可以跟影像視覺系統緊密結合,我會非常期待看到這樣的程式框架。期待明年我的疑問可以得到解答。
- 自動駕駛的部分與去年相去不遠,但是今年有一些新東西和更仔細的說明。路徑規劃的部分有說明應該如何考慮與其他物件的交互作用,Occupancy Network 的部分有提到他們生成 Voxels 技術是採用不需要神經網路也能訓練的 NeRF。最令人驚艷的是 Lane Networks 採用語言生成的方法來預測所有可能的行車路線。
- 去年我留下的疑問(怎麼利用駕駛人操作的資料來優化?)今年得到了解答,今年有提到使用物理引擎來規劃路徑速度太慢,所以他們使用神經網路來預測路徑,而這神經網路就是訓練在駕駛人操作的資料之上的。