Tesla AI Day 2021 筆記
Posted on October 09, 2022 in AI.ML. View: 1,526
原始影片:youtube
How do we make a car autonomous?
Vision

在 Full Self-Driving(FSD)的任務當中,需要利用多顆鏡頭的影像來重建出 3-D 的 Vector Space,而在這 Vector Space 中我們就可以靠著 Planing Algorithm 來駕駛汽車。
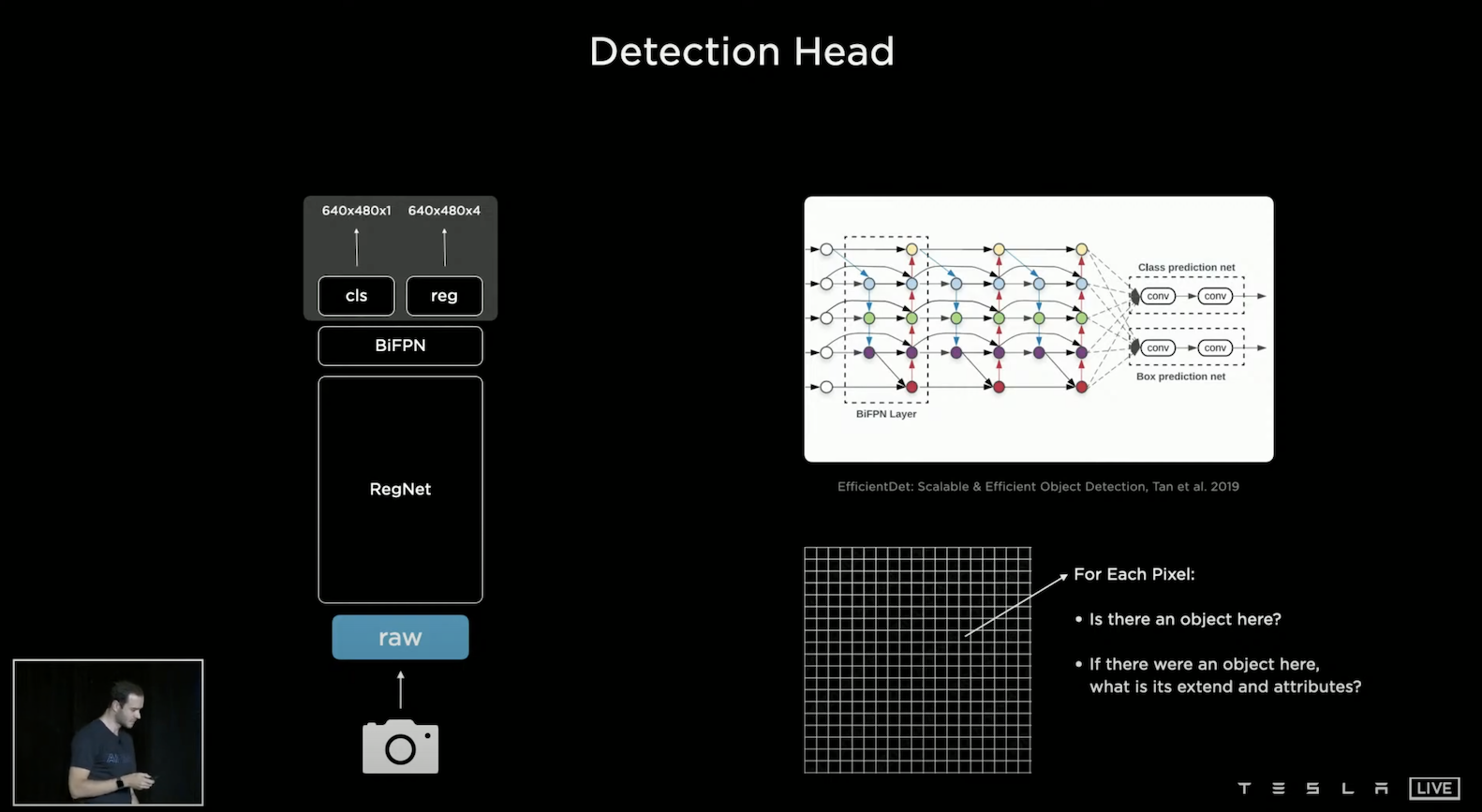
在簡單的 FSD 原型中,可以輸入一個 Frame 的圖片進入 Feature Extractor,這裡採用RegNet [Designing Network Design Spaces, Radosavovic et al., 2020],並且採用 Bi-directional Feature Pyramid Network (BiFPN) [EfficientDet: Scalable and Efficient Object Detection, Mingxing Tan et al., 2019] 來融合不同規模的資訊,Andrej 舉例當一輛車子在低解析度時無法被確認,此時如果使用高解析度的資訊就可以判別。最後就可以在其上設計 Detection Head,可以做分類任務或迴歸任務。
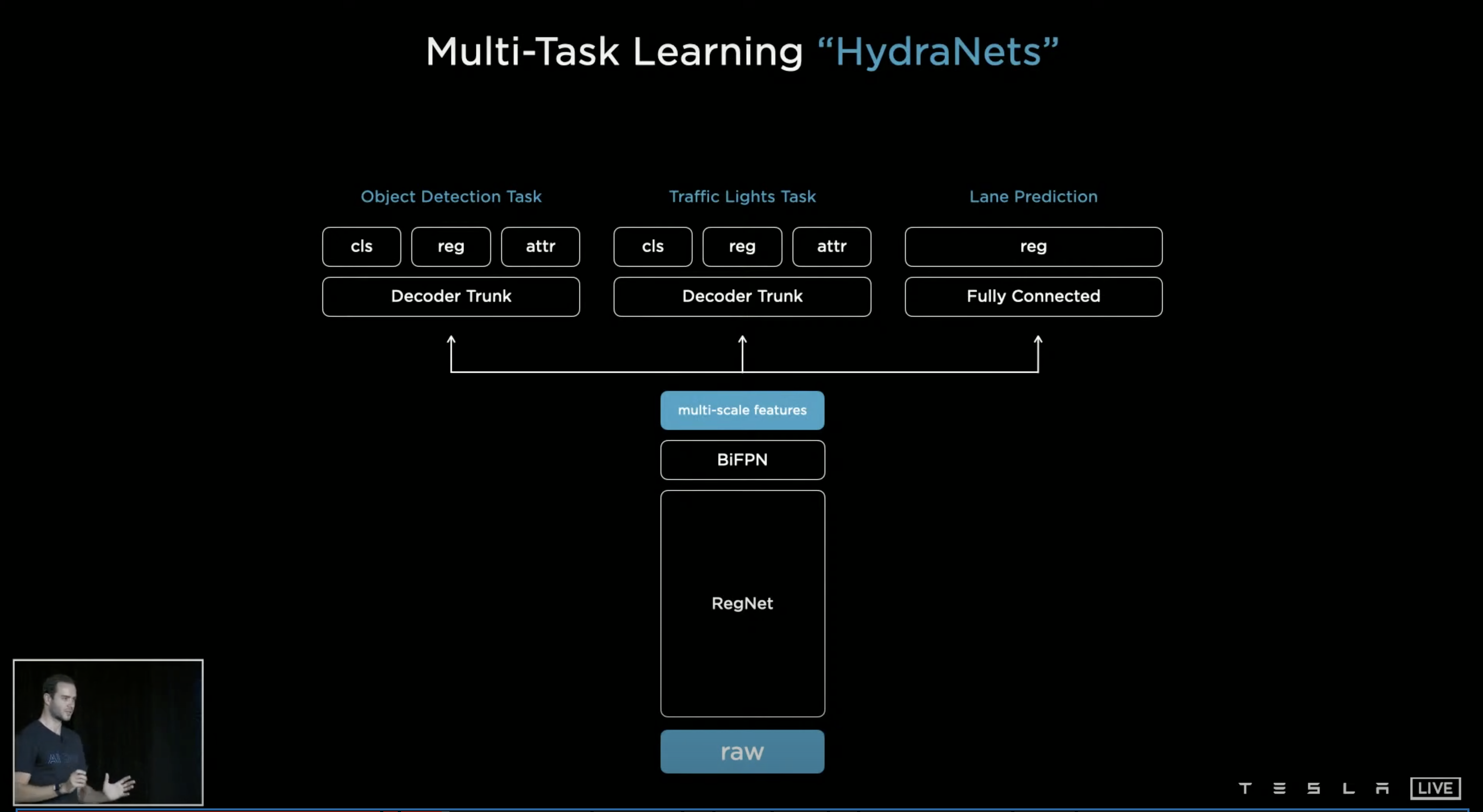
而在 FSD 中需要更多的資訊,需要物件偵測、交通號誌偵測並判別、車道預測等等,所以需要多任務的訓練,所以 Tesla 採用多個 Detection Head,整個結構稱為 HydraNets。這樣的結構帶來三點好處,第一,因為共享 Feature,這會在 Inference 時更為有效率;第二,因為各項任務的解耦合,我們可以在不影響其他任務的情況下微調單一任務;第三,因為抽出了 Multi-scale Features 的緣故,我們可以將它存起來,這帶來了使用上的彈性,有時使用暫存的 Multi-scale Features 來微調任務,而有時可以進行 End-to-end 的訓練。
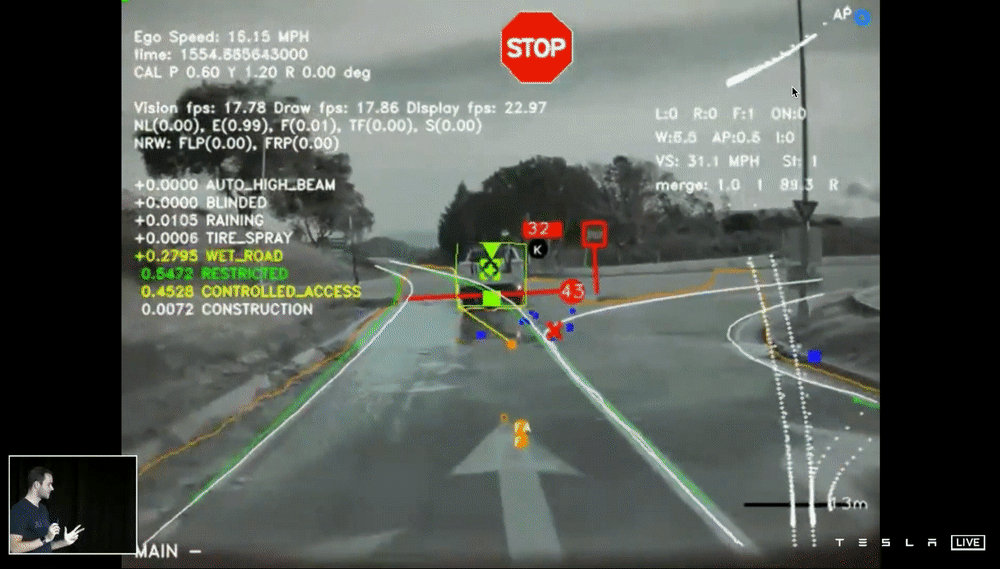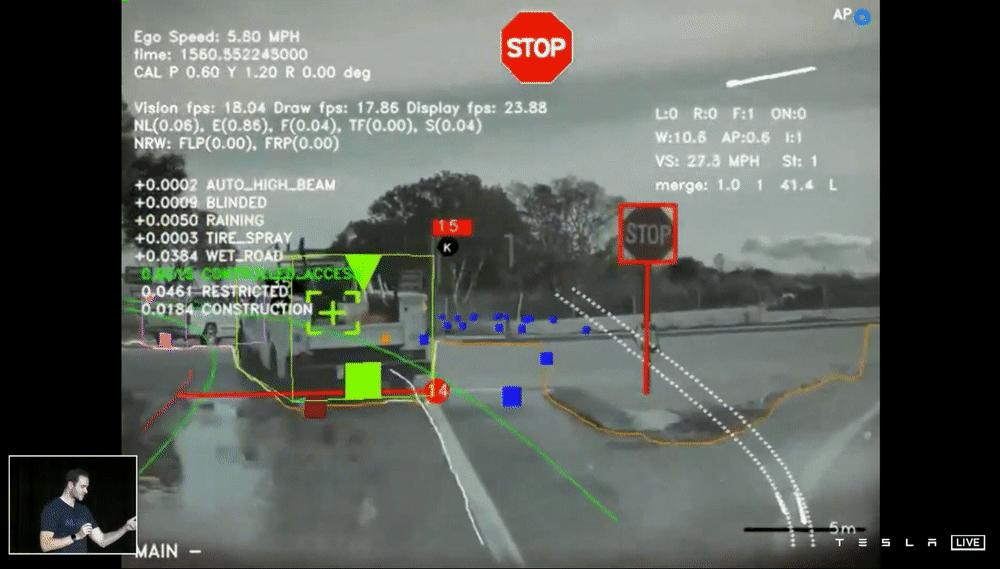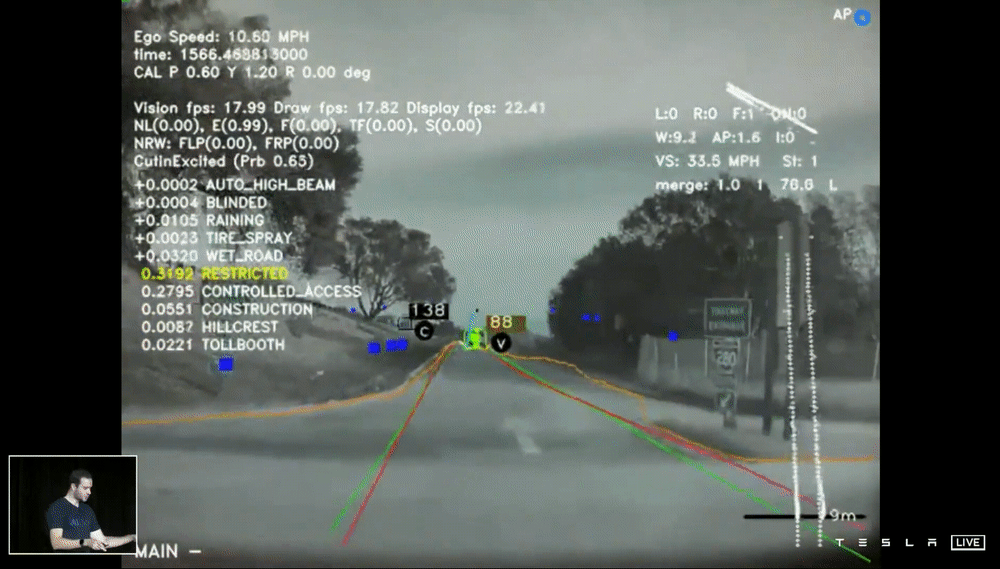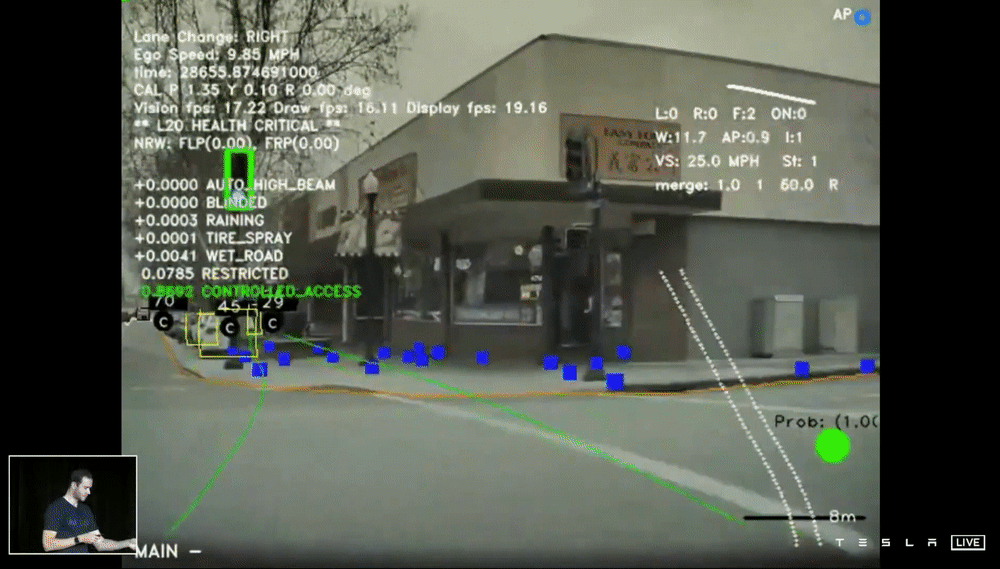
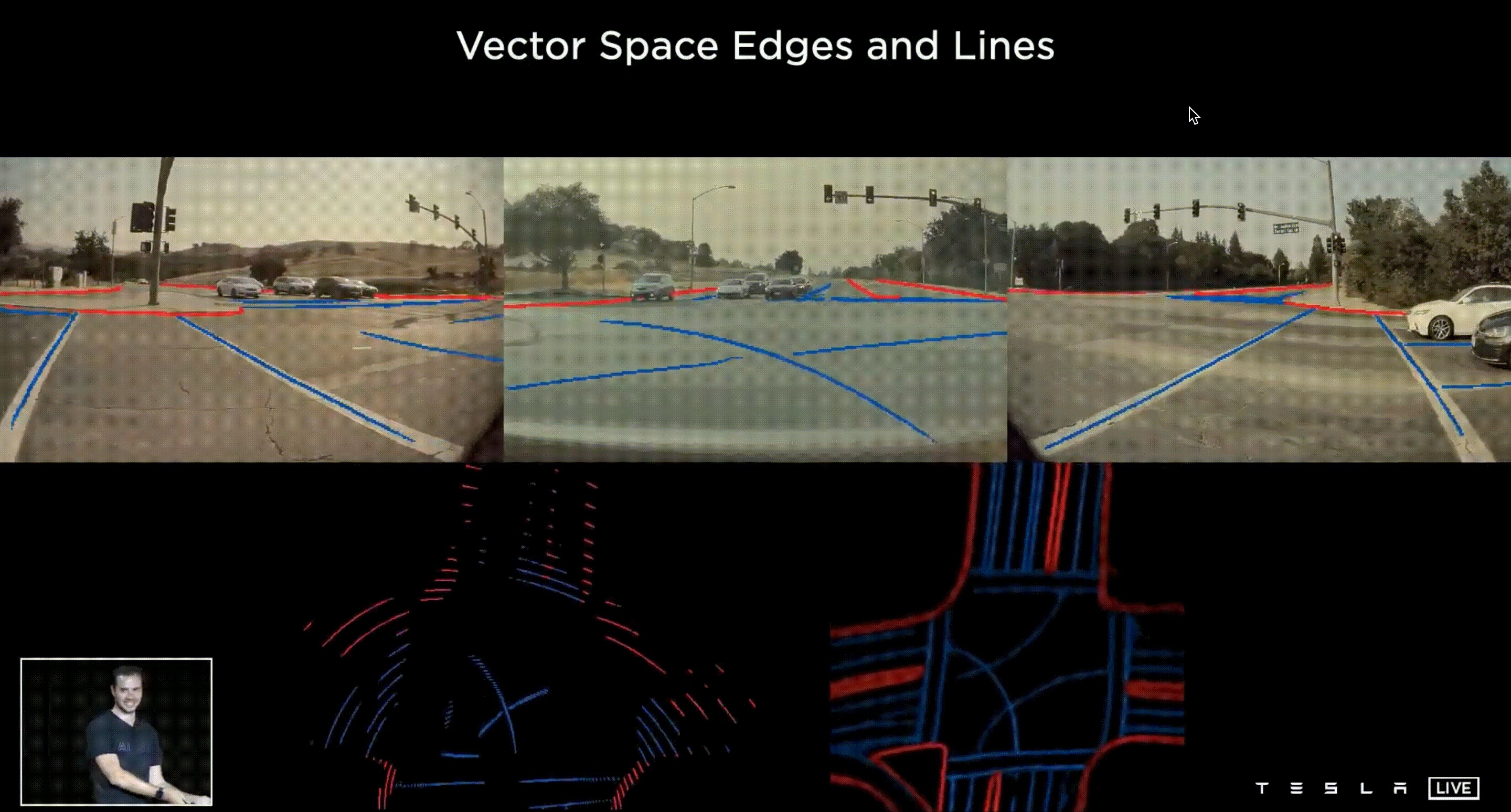
上面的demo片段是最初版本的 HydraNets 結果,特別強調這邊使用單一 Frame 的圖片進行預測,從畫面中你可以看到,模型標示著停車指示、停止線、車道邊緣、其他車輛(並指示是否為停車的狀態)、交通號誌等,看起來一切好像不錯,但是當我們想將所有鏡頭的資訊綜合轉成 Vector Space 就出現了問題。
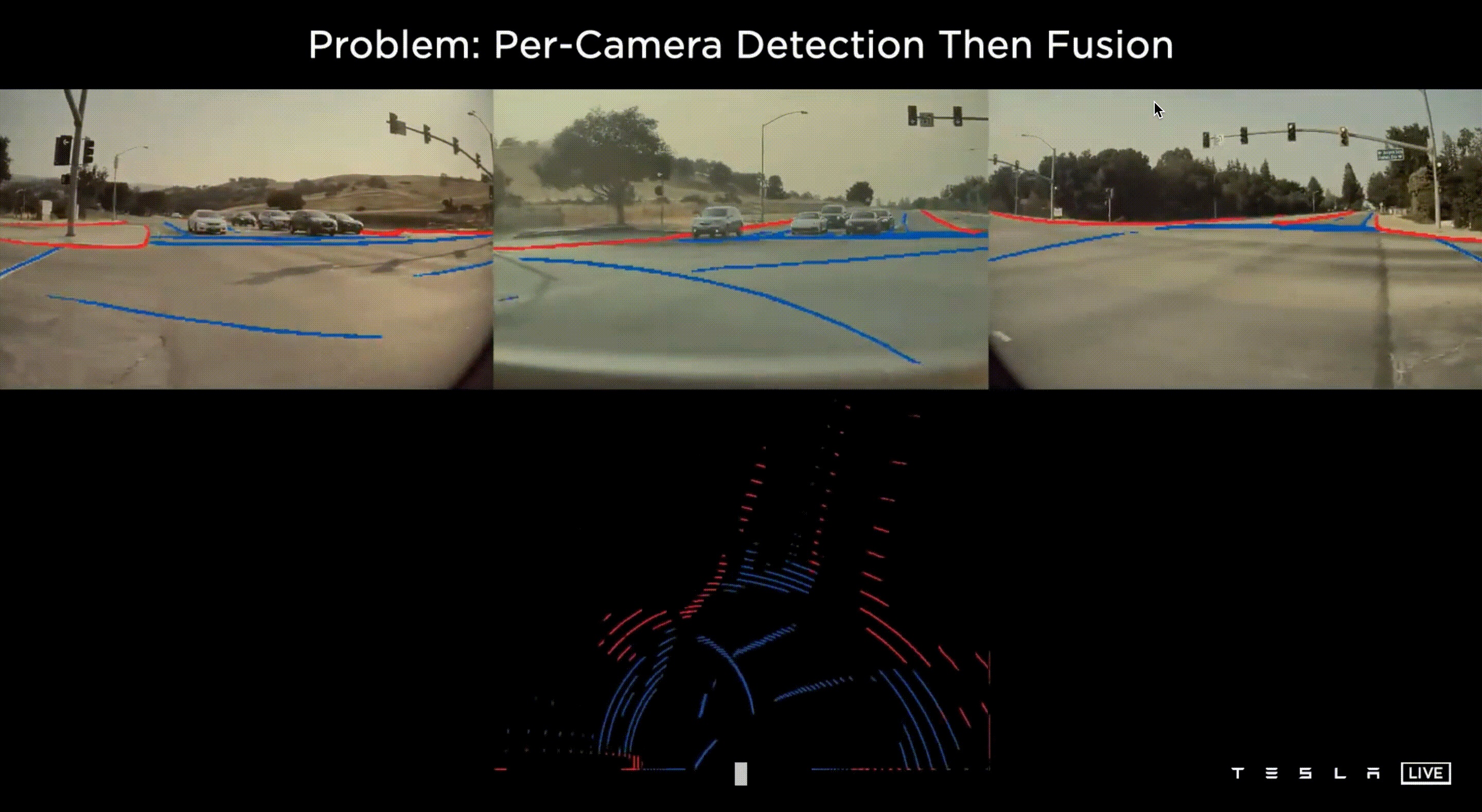
上圖揭露了問題,在每一個鏡頭下的每一個 Frame 都能清楚的預測標線,但是當我們想要利用這些資訊建立 3-D 的 Vector Space 時候,就會發現其匹配的狀況並不良好,從鳥瞰圖看來所有的線並不能正確的貼齊,效果相當差,原因在於每個圖片在預測深度時存在著誤差,誤差疊加之後就造成 Vector Space 的訊號不穩定。
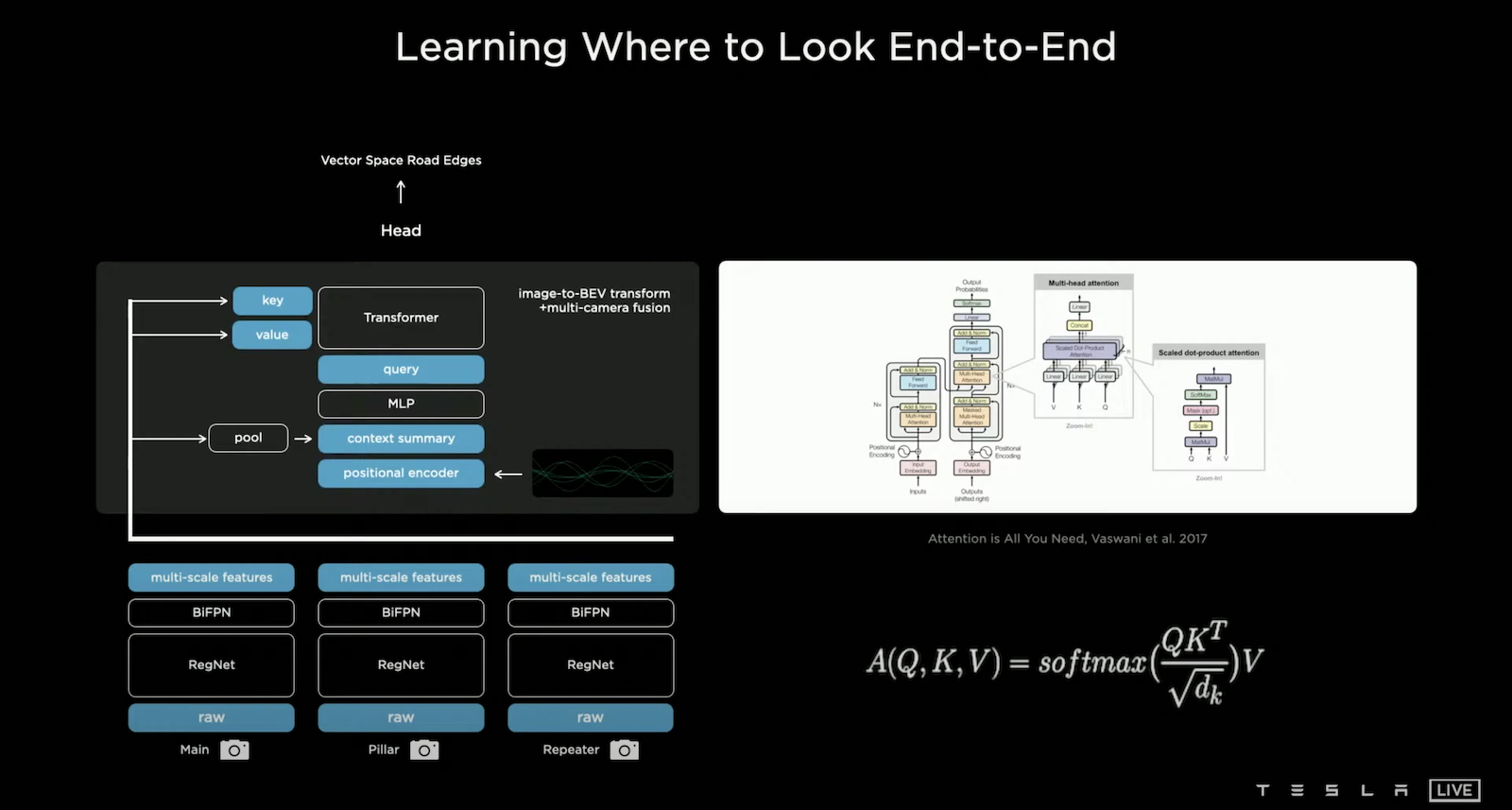
於是乎 Tesla 的研發團隊打算另闢蹊徑,假設我們直接 End-to-End 的讓模型直接輸出 Vector Space,是不是就可以解決這個問題,舉個例子:當一輛卡車出現在八個鏡頭中的五個,如果使用每個鏡頭都獨立判斷的方式,模型難以感知這是同一輛卡車,但是如果我們可以綜合八顆鏡頭的資訊並且直接輸出 Vector Space,就有機會讓模型學習到這五個鏡頭內的卡車是同一輛,並且落在 Vector Space 的某個地方。要往這方向前進會先遇到兩個問題:1. 怎麼從 Image Space 轉成 Vector Space? 2. 要做到 Vector Space 的預測,我們要有在 Vector Space 標注的資料集。問題2我們會在後續討論,而問題1的解法是引入 Self-attention [Attention Is All You Need, Vaswani et al., 2017] 來結合八顆鏡頭的 Multi-scale Features 產生 Vector Space 的 Features。
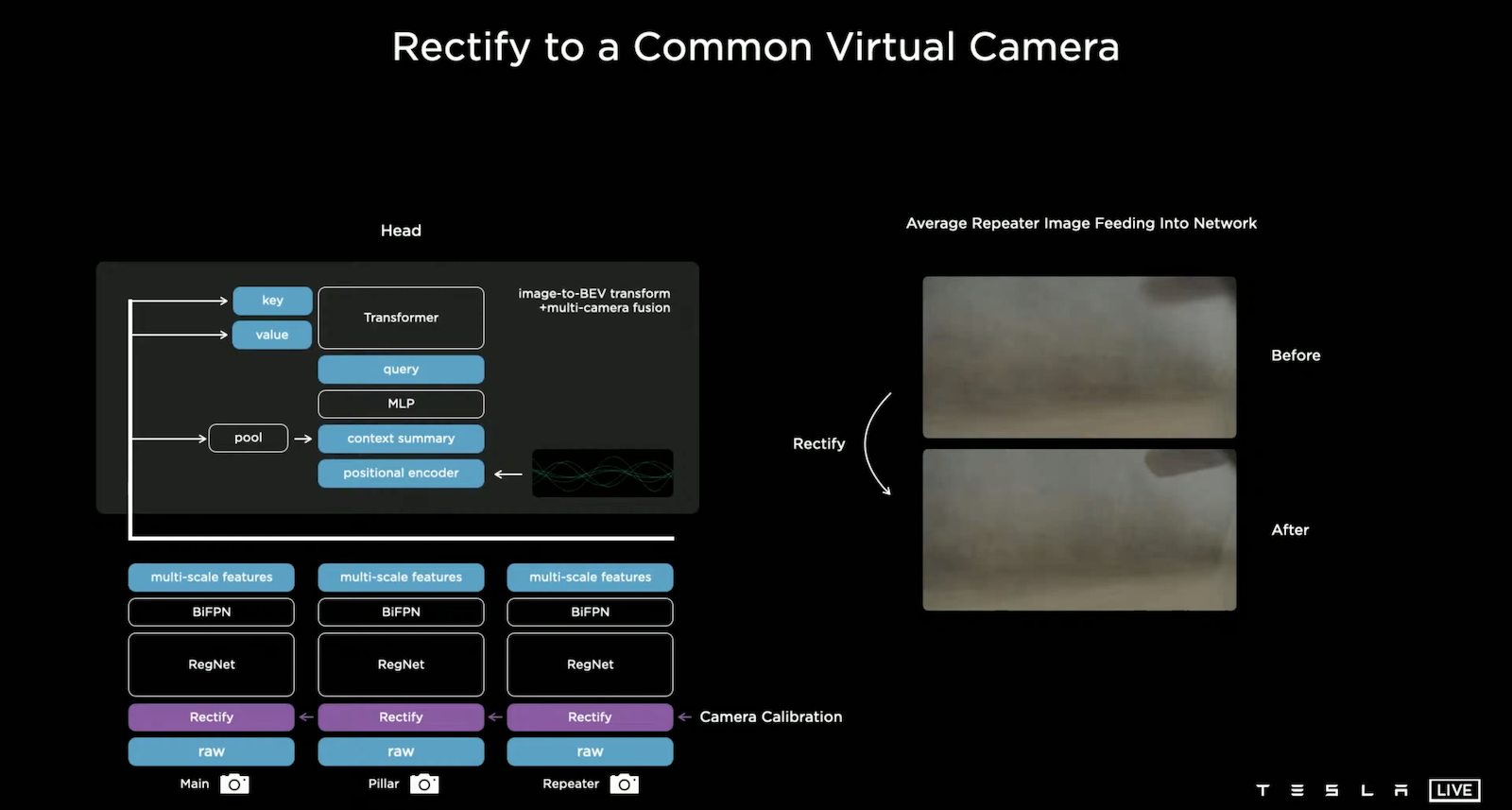
由於每輛出場的車輛其八顆鏡頭的參數可能存在著差異,如果將這些有差異的影像輸入到單一模型就可能達不到原有的效果。而 Tesla 的作法是將每顆鏡頭先做 Camera Calibration (Rectify Layer),具體的作法是將八顆鏡頭轉換到 Synthetic Virtual Camera 作校正。上圖右側顯示校正前後的差異,其中將後側鏡頭(Repeater)的影像疊加,可以發現校正後圖片變得清晰了,這意味著所有車輛在調整完鏡頭後影像更為一致。
上圖右側的鳥瞰圖是 End-to-end 的結果,預測在 Vector Space 成效就明顯的提升了。

在多顆鏡頭一同學習的幫助下,可以有效的解決遮擋的問題,能更穩定的預測周遭車輛。
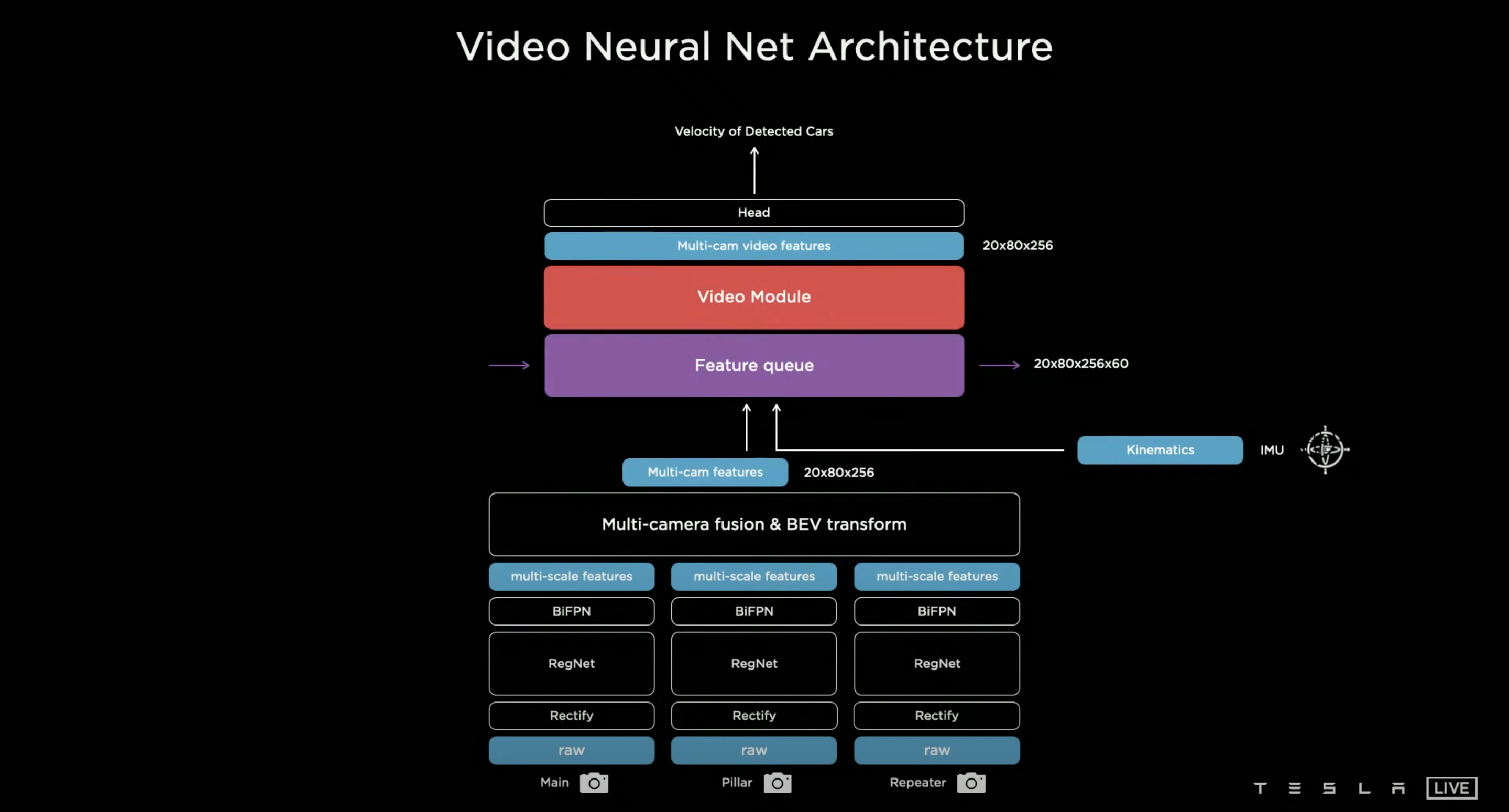
Tesla 的研究小組發現有一些預測需要上下文的資訊,於是他們設計一個 Feature Queue 並將每一個時間段 Frame 的 Feature 推入,並且利用 Video Module 去綜合萃取 Feature,Video Module 能更加穩定的預測周遭車輛。
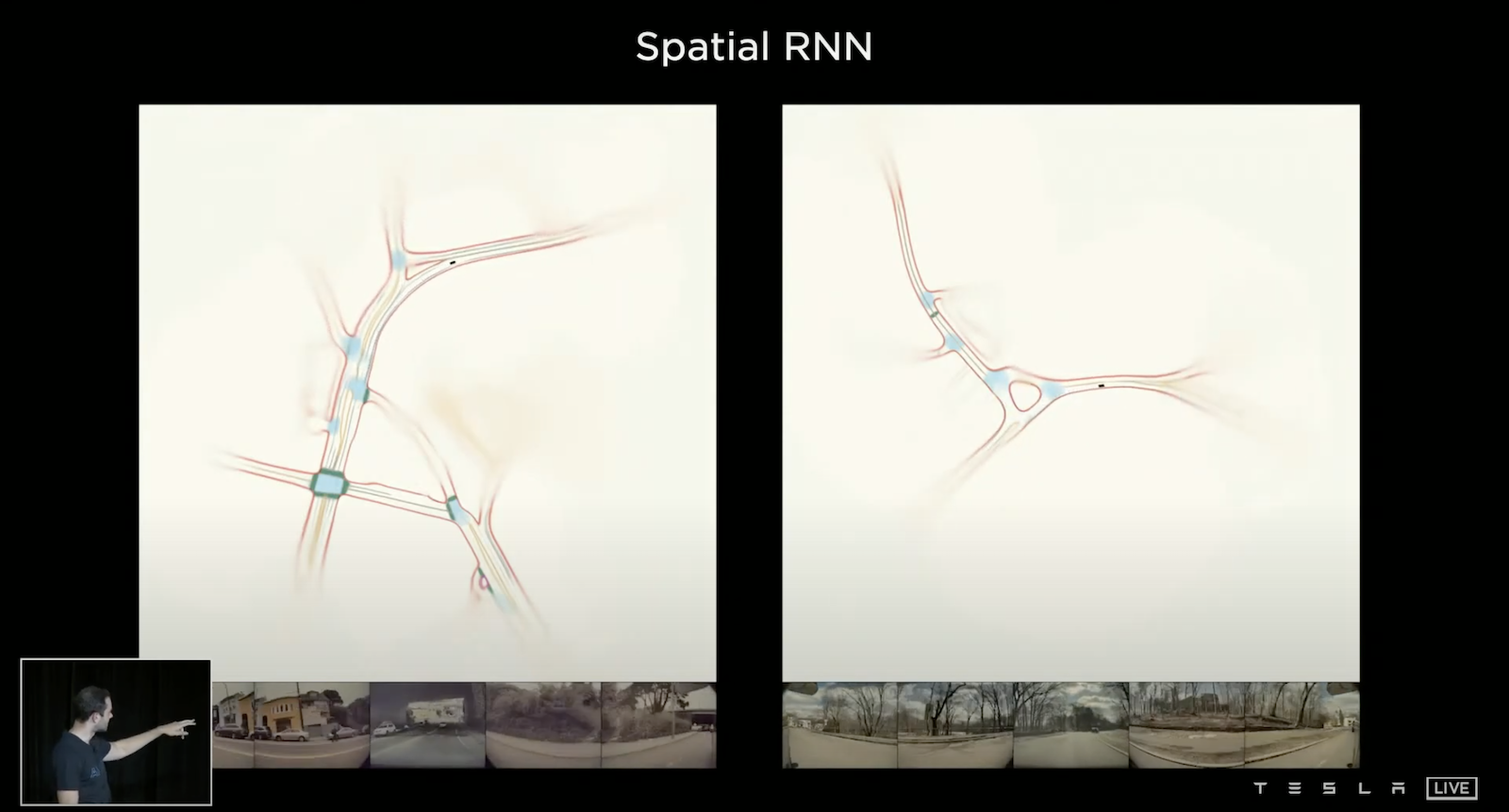
除了時間尺度之外,他們還考慮了空間尺度,譬如左轉或右轉的標誌可能在先前的路上顯示,我們不能因為車輛等個紅燈就忘記了先前這些重要的資訊,所以除了時間尺度上的紀錄,我們還需要空間尺度上的紀錄,於是他們提出了 Spatial RNN 的方法在每一個空間點持續演化其 Feature,更棒的是不同 Tesla 車輛是可以共用這個空間 Feature Queue 的,所以經過不同車輛、不同時間、不同地點的大量蒐集資料,Tesla 精準的掌握豐富的資訊地圖。
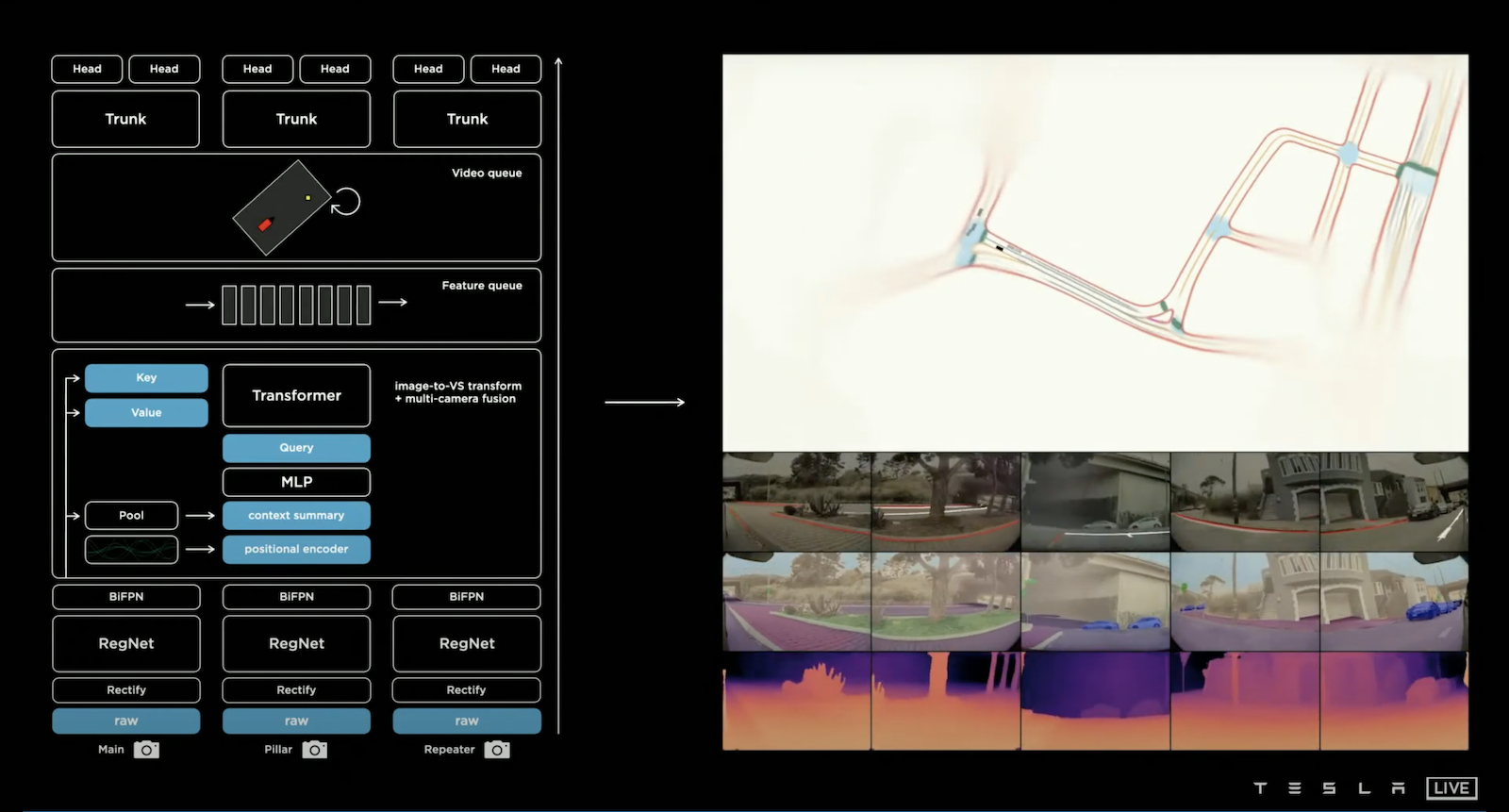
以上就是 Tesla Vision 模型的大架構。
Planning & Control
我們已經有了由 Tesla Vision 建立的 Vector Space,接下來我們就可以在這個空間裡開車,但這不是一件簡單的事,會遇到 Non-Convex 和 High-Dimensional 兩個問題。Non-Convex 意味著路線規劃中存在著多條足夠好的路徑,但是想要找到全局最優的那個路徑會變得困難,很有可能會卡在局部最優解;High-Dimensional 的原因是因為車輛需要為接下來10-15秒做規劃,要估計這一個時間區間的位置、速度、加速度,因此要描述一整條路徑是高維的。
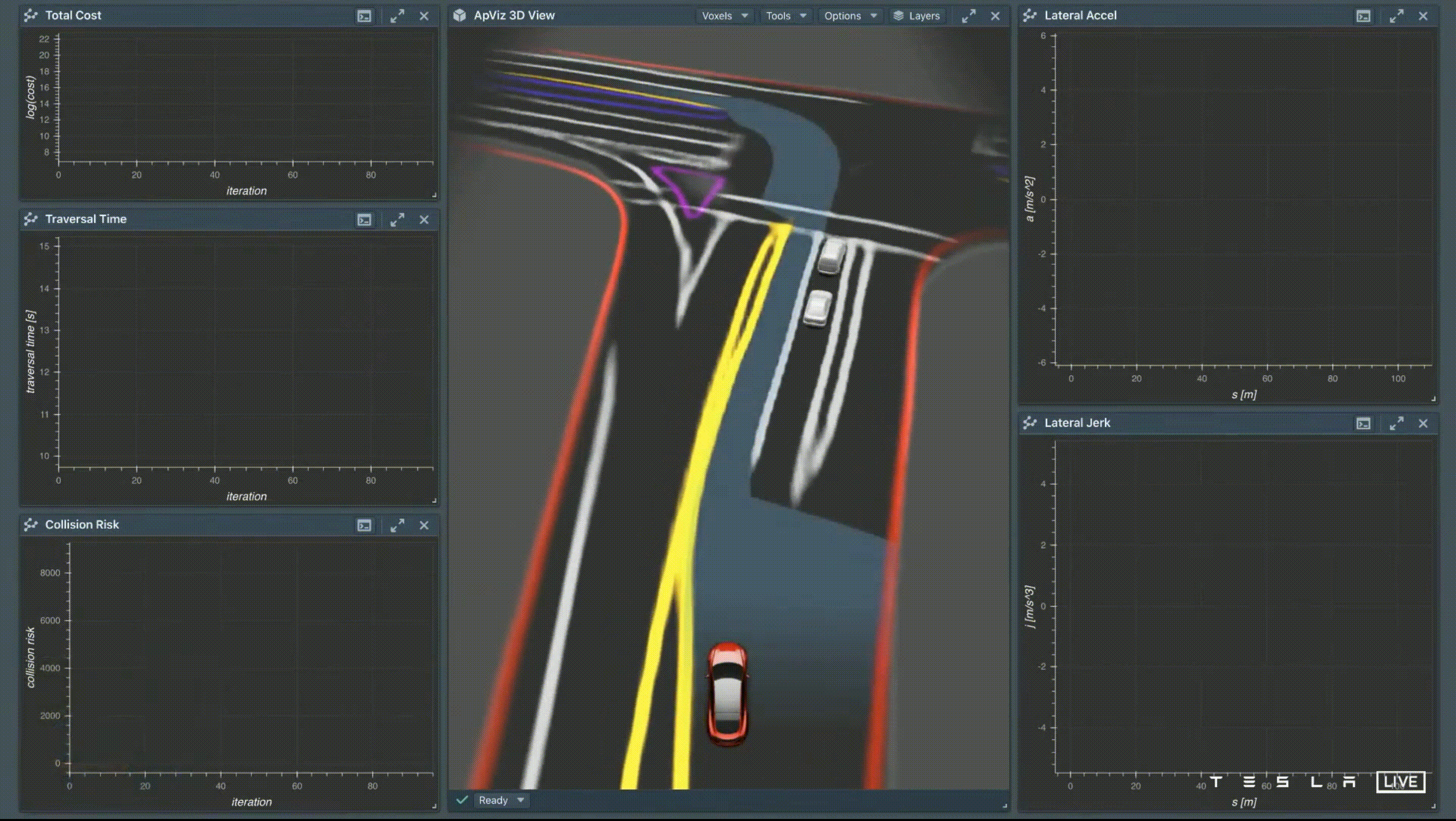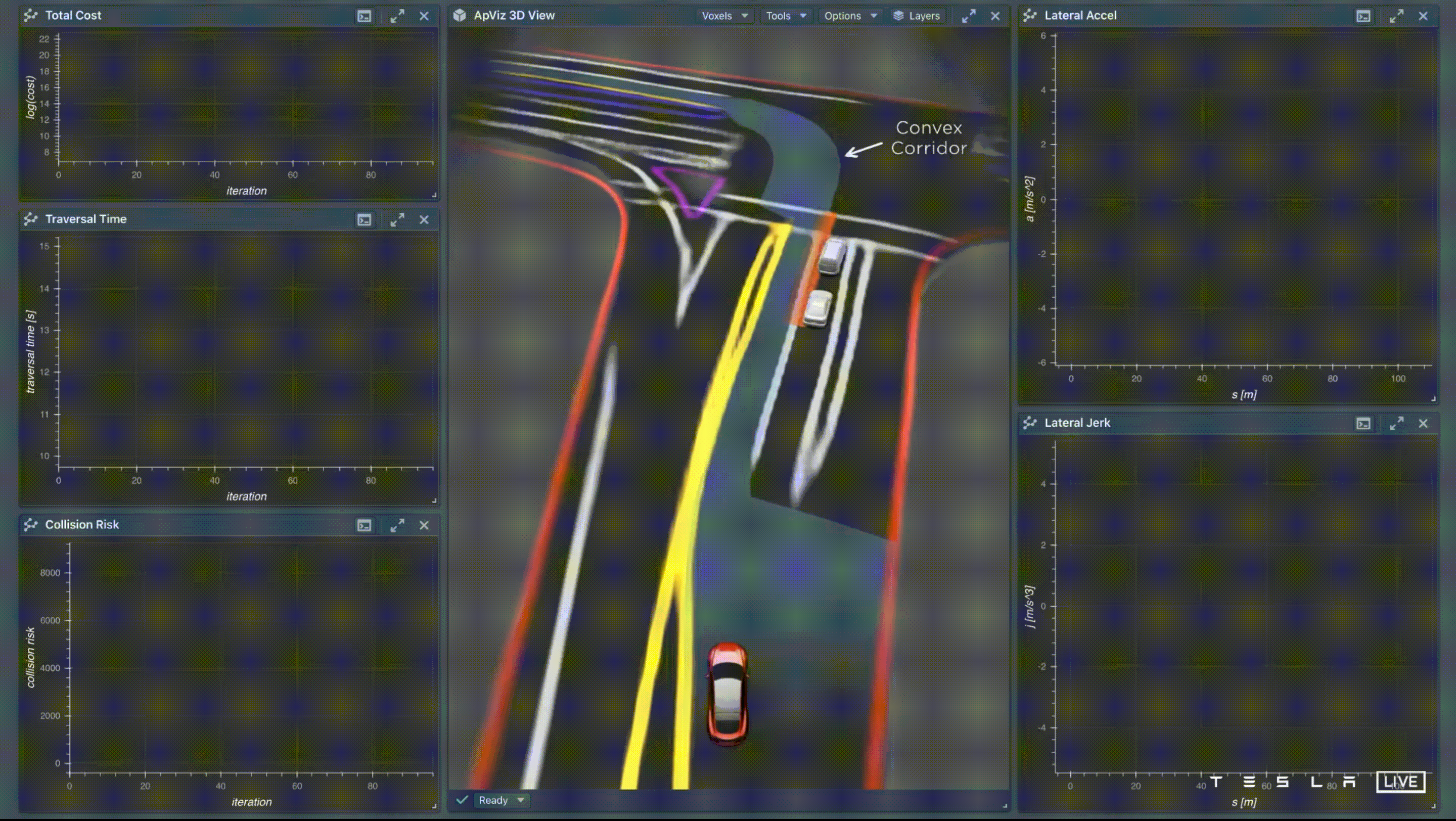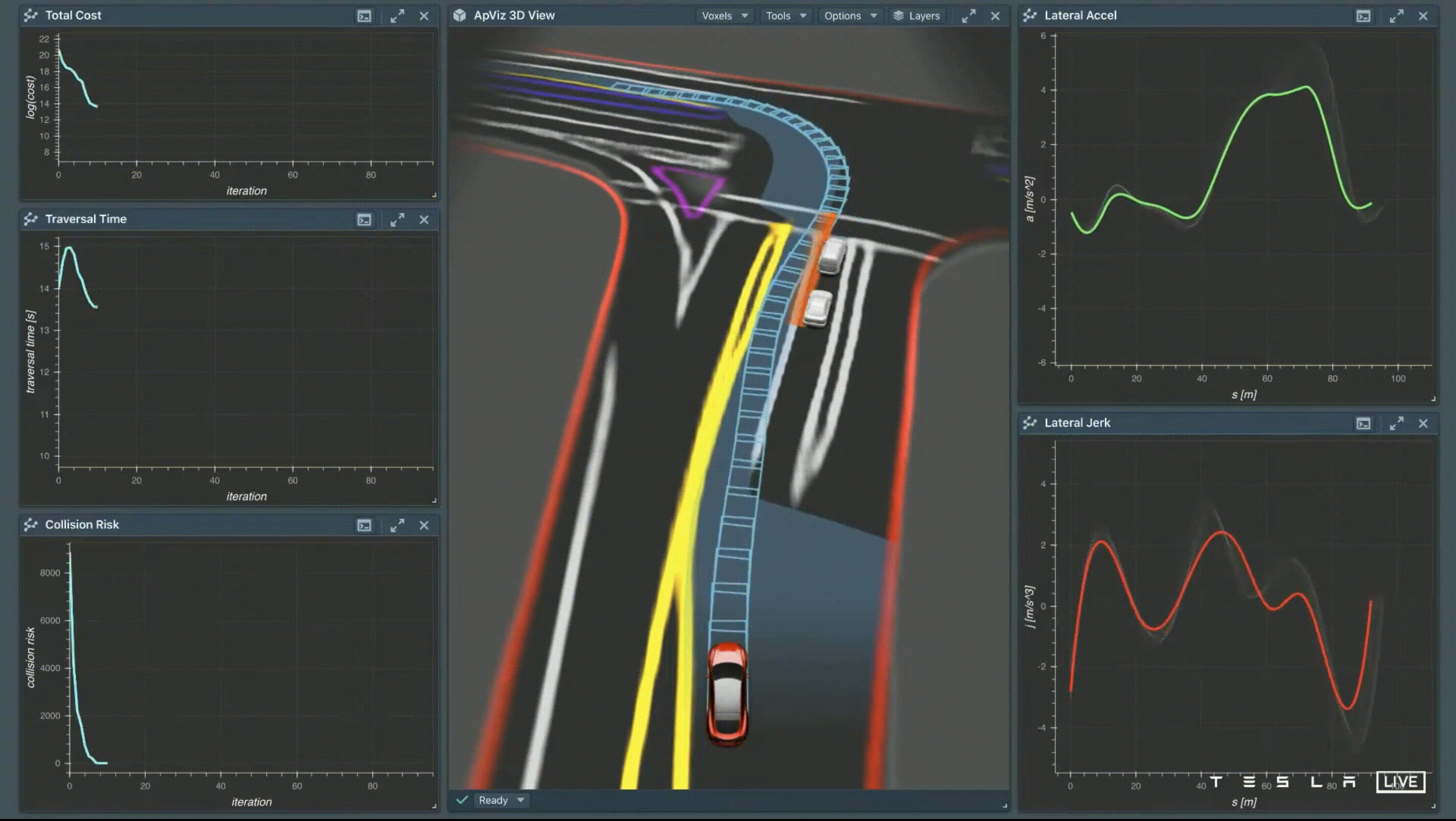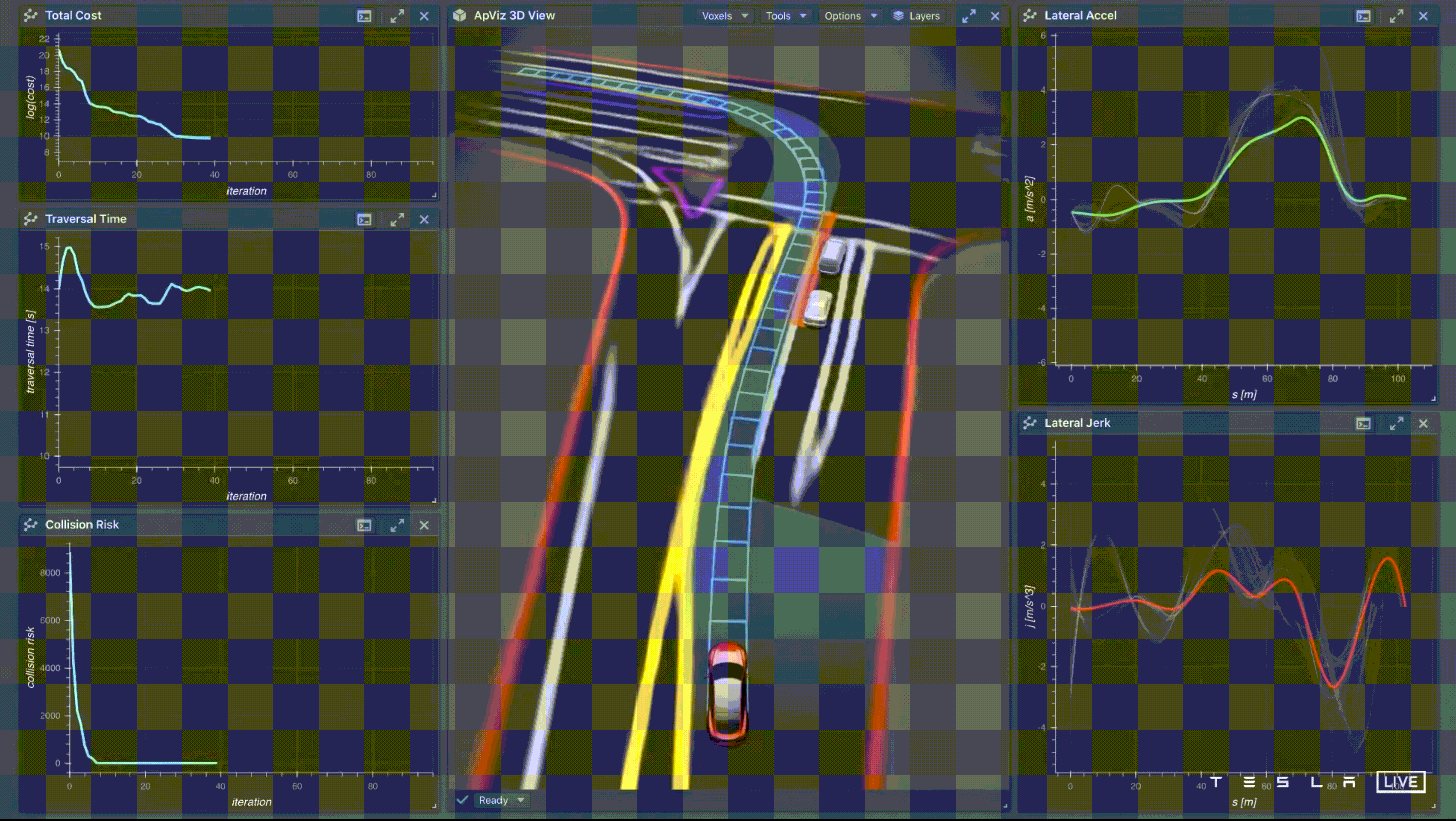
優化方法有兩種策略 — Discrete Search 和 Continuous Function Optimization,但這兩種策略都有侷限性,Discrete Search 用在 High-Dimensional 的情況下會造成計算複雜度相當高,而 Continuous Function Optimization 用在 Non-Convex 容易陷在局部最佳解,因此 Tesla 的解法是採用混合式,先使用 Discrete Search 來建立一條可走的通道,來侷限路徑,稱為 Convex Corridor,再使用 Continuous Function Optimization 的方法找出一條平穩的路徑。
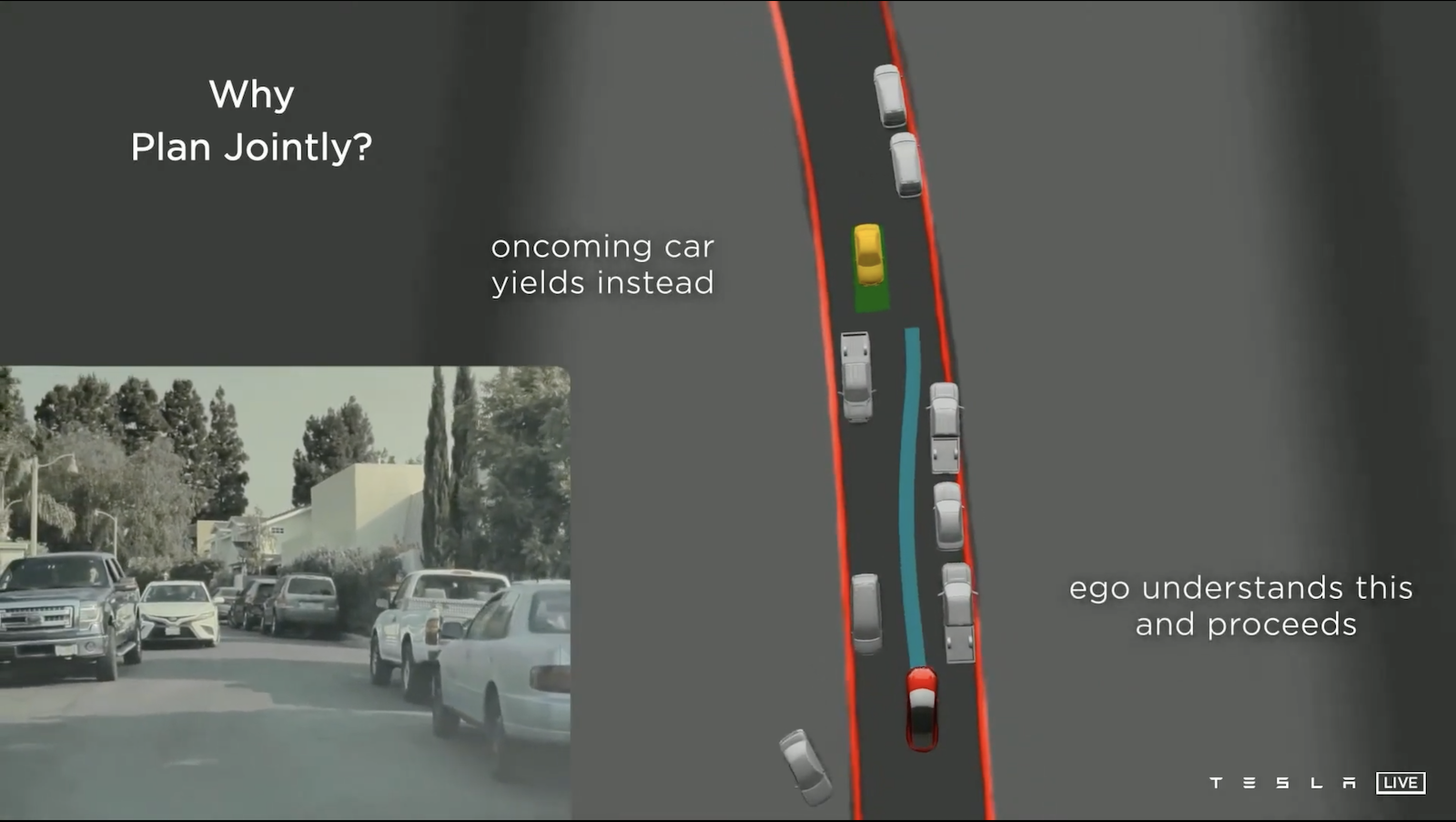
另外,我們在做行車規劃時還需要考慮其他車輛的移動,例如遇到會車的狀況,自動駕駛要能分辨來車是否要讓道,如果對方讓道,我們的車子前進;如果對方不讓道前進,我們的車子要讓道。
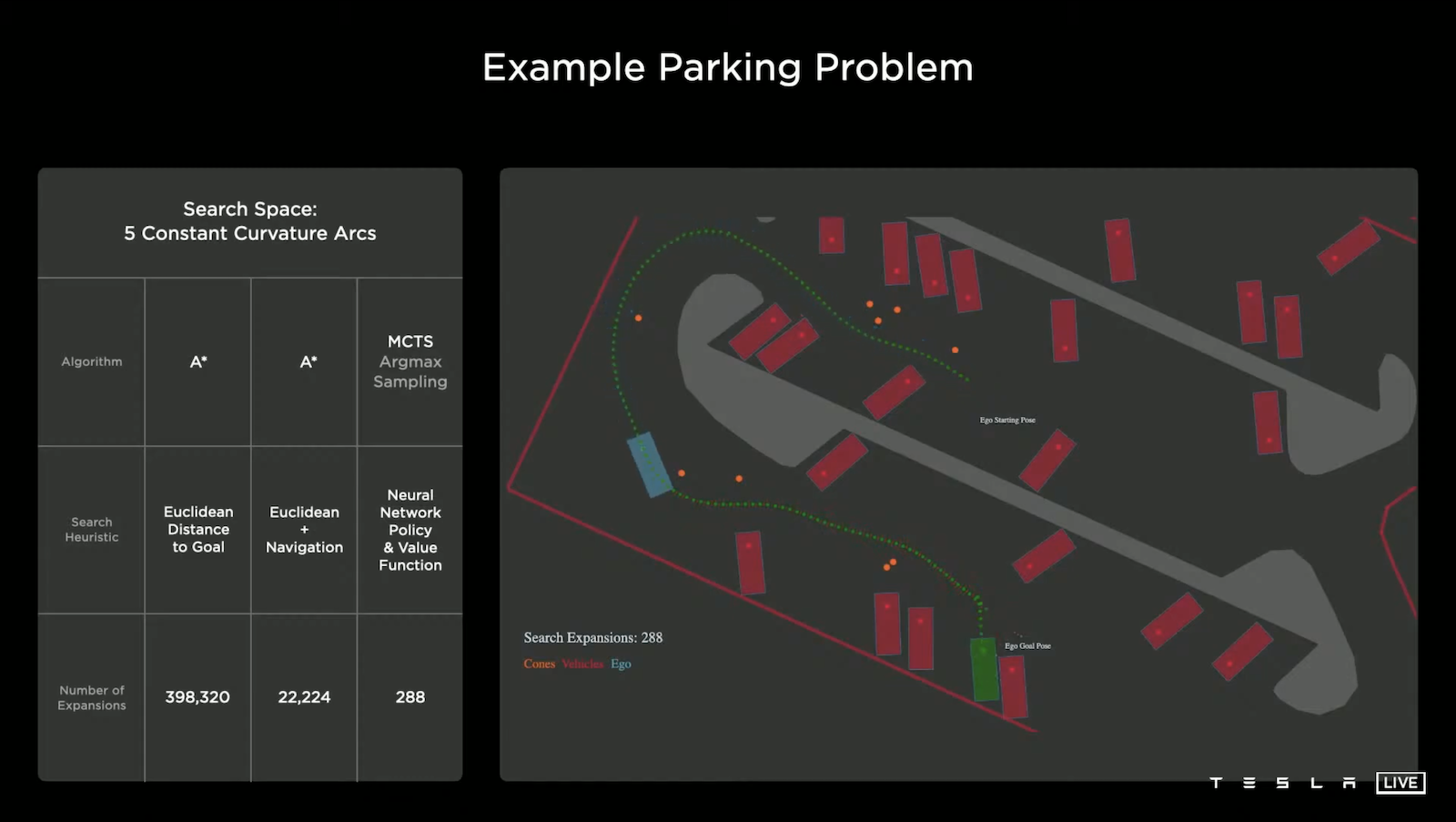
在一般道路,尤其是高速公路,路徑搜索還算簡單,但是有一些狀況卻是相當棘手的,例如:停車問題。如上圖,停車場充斥著許多障礙物,在路徑搜索中最常見的方法是使用 A* 演算法,但是這個簡單的方法展開次數要多達近40萬次,這樣的運算速度是不能接受的,所以 Tesla 再進一步加入行進方向導航,可以讓 A* 演算法進步到展開次數大概2萬次,但這仍然不夠快速。原因是因為目前作法並不能綜觀全局(使用鳥瞰圖)來找路徑,於是我們借助神經網路的幫忙,利用類似AlphaGO的方式來做路徑搜索,結果展開次數可以降到近300次而已,差異相當的巨大。
How do we generate training data?
Manual labeling
演算法僅僅提供了效能的上界,我們還是需要充足的資料來調整演算法的參數,所以建構一個品質良好且量大的資料集是重要的,因此 Tesla 聘僱了大約1000名專業的標注人員進行標注,並且開發了專屬的標注軟體。在一開始他們是在2維的圖片上面標注,後來如上述所提及的,模型要直接預測 Vector Space 才能表現的夠好,所以他們開始在 Vector Space 上標注,直接標注在3維的空間加上時間尺度。
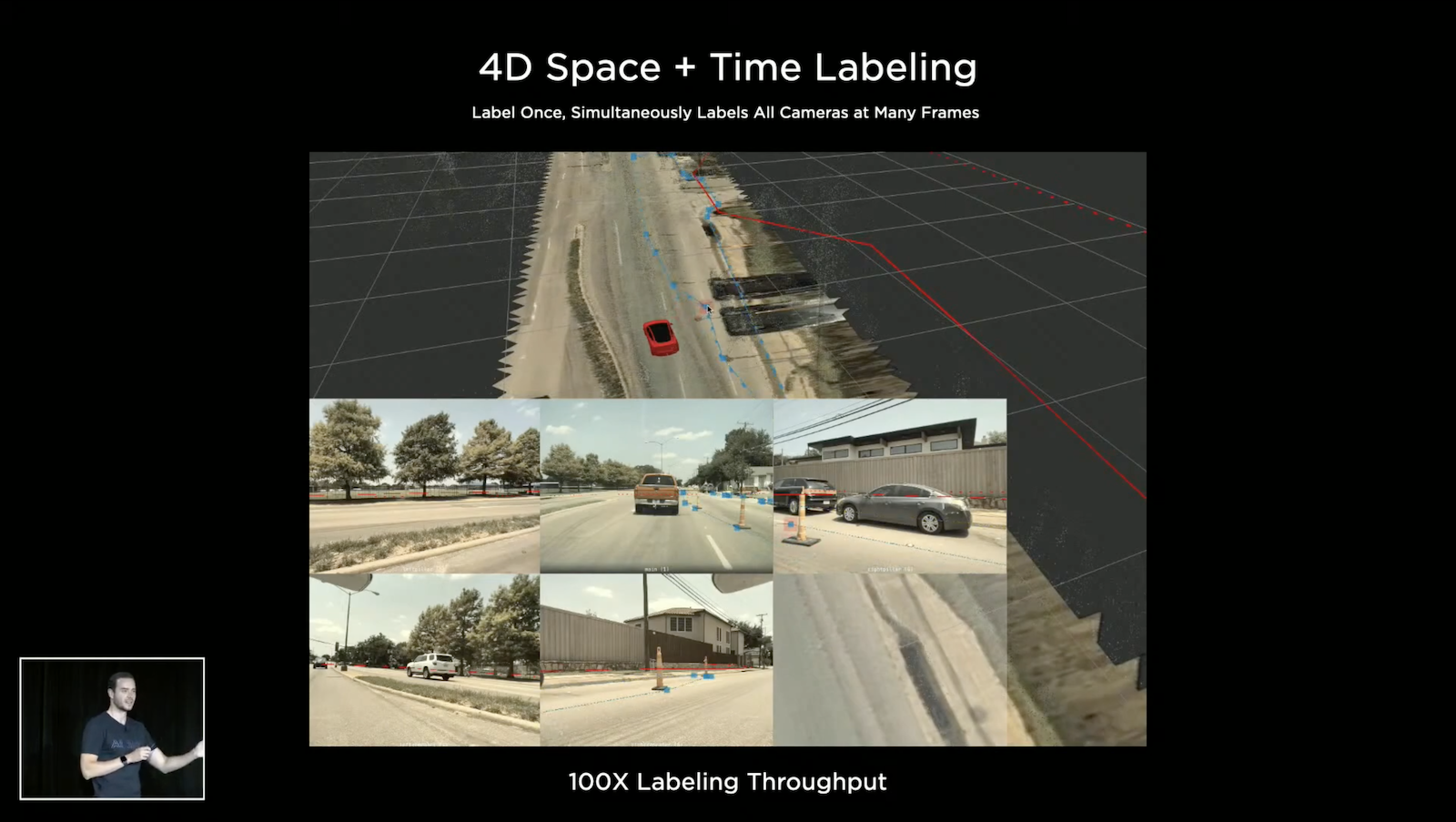
Auto Labeling
人與電腦擅長的東西不同,人擅長語意相關的東西,而電腦擅長幾何、重建、追蹤等等,所以 Tesla 的標注軟體充分利用兩方的所長,進行人機協作,來更快速的建立良好的資料集,這就是Auto Labeling的技術。
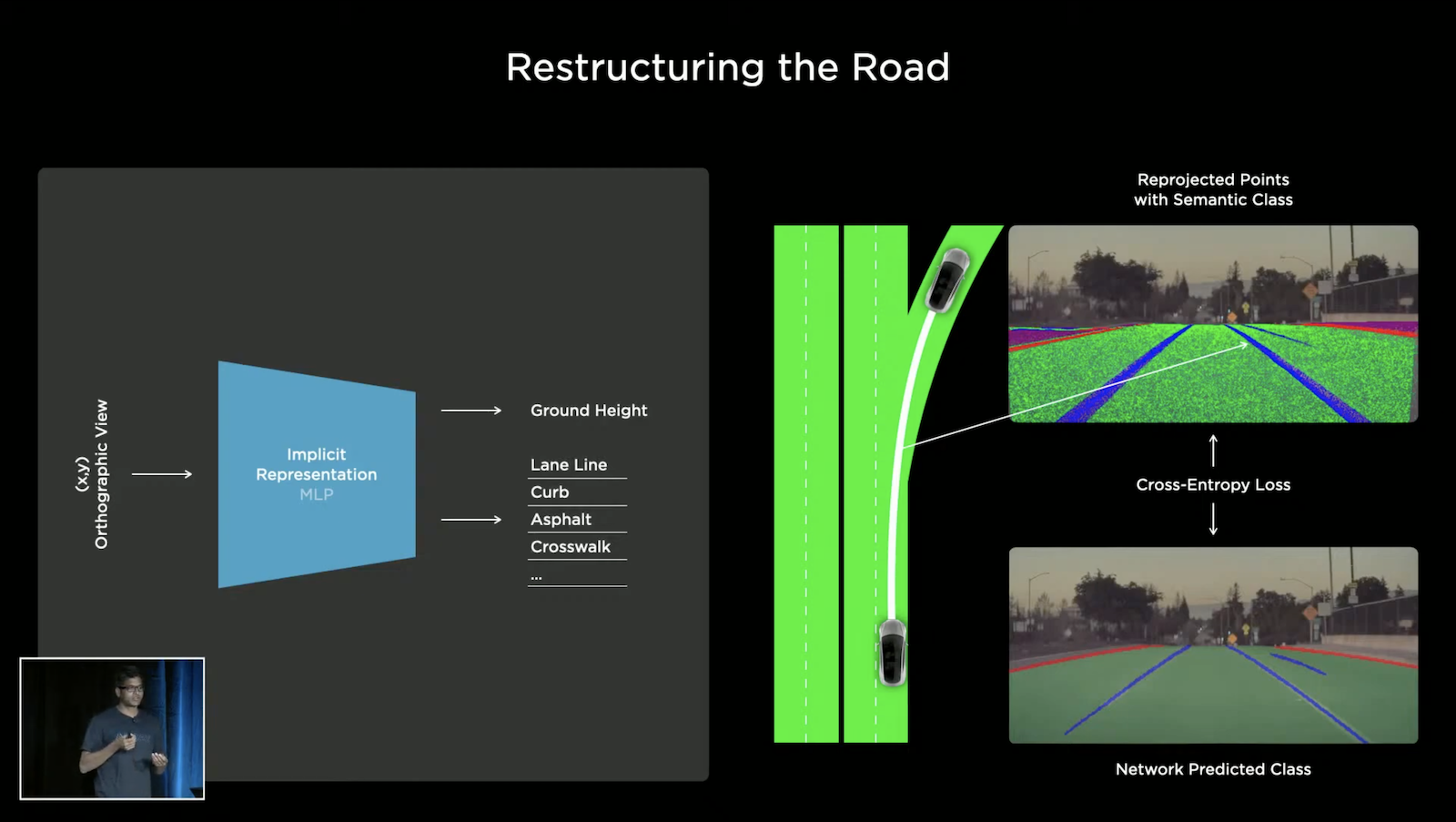
Tesla 會從車輛上蒐集影片的資料,並上傳至伺服器 Dojo,利用這些資料我們就可以重建整個道路,如上圖左側的圖例,輸入 (x,y) 座標查詢地面高度、道路指示線、路緣等等。你可能會想利用三維網格來描述路面,但因為拓撲的限制,這樣的表示是不可微分的,並不適合重建或生成,所以他們實際的作法是用類似於Neural Radiance Fields (NeRF) [NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis, Ben Mildenhall et al., 2020] ,NeRF 能做到利用多個角度鏡頭的拍攝來重建三維資訊(當然,必須要有這些鏡頭與拍攝物的空間相對關係),而 Tesla 的八顆鏡頭正提供了這個設置,NeRF 的精髓在於將物體和場景的資訊以隱性的方法編碼進 MLP 中,所以當我們輸入 (x,y) 座標到 MLP,我們可以獲得我們想要的空間資訊。經過大量的查詢 (x,y) 得到 z,我們就可以將路面給建構起來。
更棒的是,每一輛行走的 Tesla 車輛都會持續蒐集並重建這些路段,有些路段還很有可能由多輛 Tesla 電動車一起建構來消除雜訊,所以愈多 Tesla 電動車在路面上開,獲得的資料就越全面、越精確,自動駕駛的穩定度就更高。

同樣的技術要重建靜態物也是沒問題的。

利用這樣的 Auto Labeling 技術 Tesla 成功的在三個月內將光雷達給移除,初期因為資料不夠充足,如果遇到視線不佳的情況,預測將會失準,如上圖左側所示。為了解決這個問題,Tesla 團隊從大量車輛中找尋類似視線不佳的影片一萬枚,並且利用 Auto Labeling 技術自動標注,大概只花了一週就完成,而這在過去採用純人工標記可能需要好幾個月,結果模型在加上這樣的資料集訓練後,就能在視線不佳的情況下做出良好的預測,如上圖右測所示,縱使視線不佳也能穩定的預測前方車輛,這為 Tesla 帶來移除光雷達的信心。
Simulation
Tesla 團隊也嘗試的使用模擬的方式人工合成影像資料來訓練模型。

使用模擬的一大好處是 Label 會同時產生,他可以幫助我們創造一些不容易出現的場景,例如:有人在高速公路跑步,或者創造出不容易標注的場景,例如:有一群人在走動同時存在著大量的遮擋問題。人工合成資料可以補足真實世界資料的不足,那要怎麼創造以假亂真的合成資料呢?有五個特點:
- 精確傳感器的模擬:模擬的目的不是為了好看,而是要能反應真實,例如在不同相機曝光度的調整下,模擬的要盡可能接近實際的狀況,為了做到這一點,他們對傳感器進行建模,包括:傳感器噪音、運動模糊、光學失真、前燈傳輸、擋風玻璃折射特性。
- 保持模擬的擬真:使用抗鋸齒算法,甚至是光線追蹤技術,來讓模擬更真實
- 多樣的場景配置
- 基於算法的場景生成:盡量減少在場景生成時的人員介入,讓這項技術可以大量生成多樣的場景,雖然可能大部分的合成資料模型都預測的不錯,但是他們會針對那些模型沒辦法預測好的場景多產生一些資料讓模型學習
- 場景重建:更神的是,他們可以將真實世界的片段轉化成為虛擬的場景,如此一來就可以針對困難的場景多生成多筆資料
Dojo
為了應付自動駕駛的龐大計算量,Tesla 還自建了他們自己的超級電腦—Dojo。

Tesla 幾乎重頭打造整個系統,從晶片設計,到集成電路,到計算叢集,還有軟體設計。

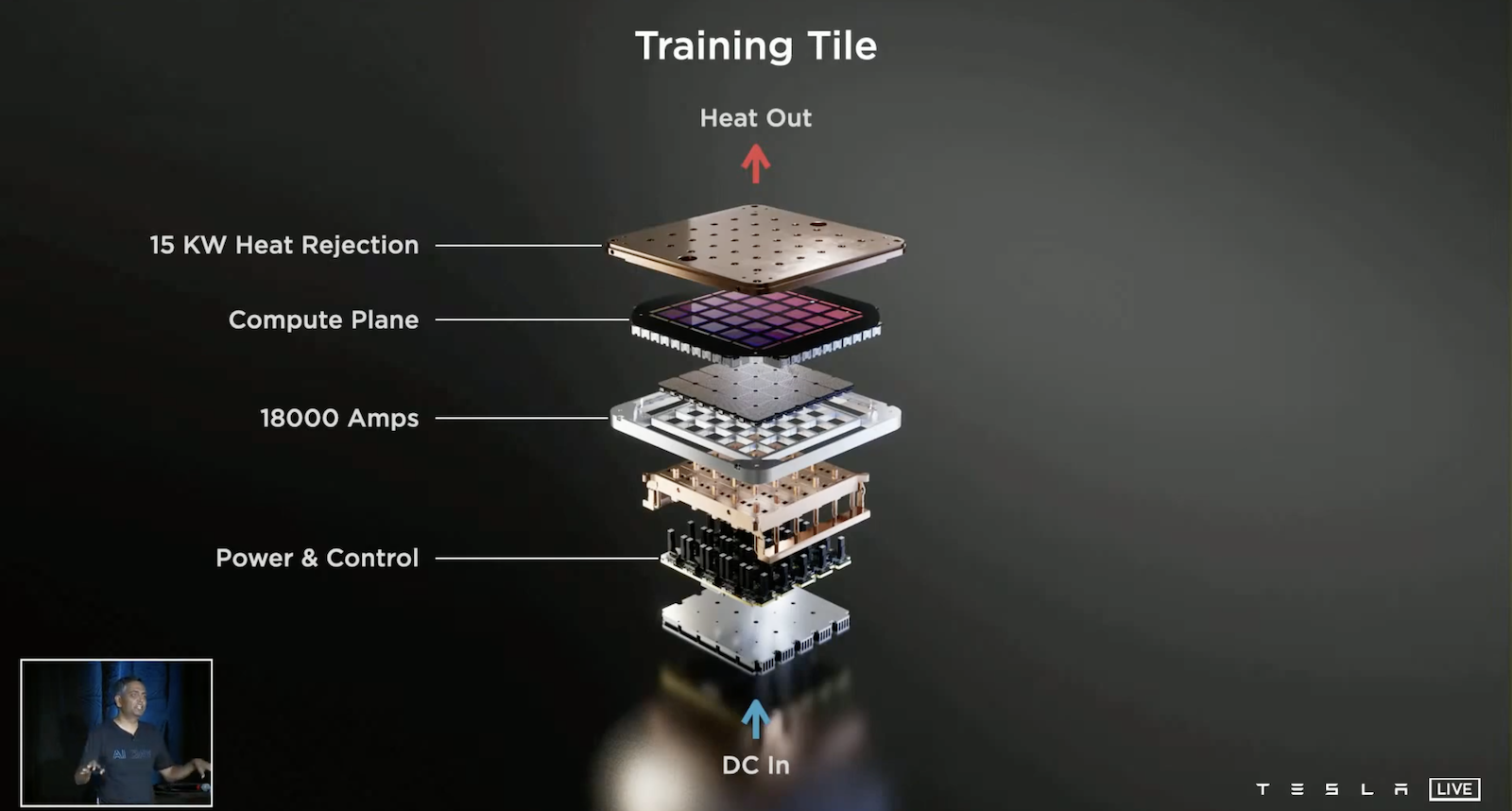
上圖展示了訓練節點的內部結構,這是一個64位Superscalar CPU,圍繞著矩陣運算單元和向量SIMD進行優化。這個節點可以提供每秒1萬億次的浮點計算(FLOP)。
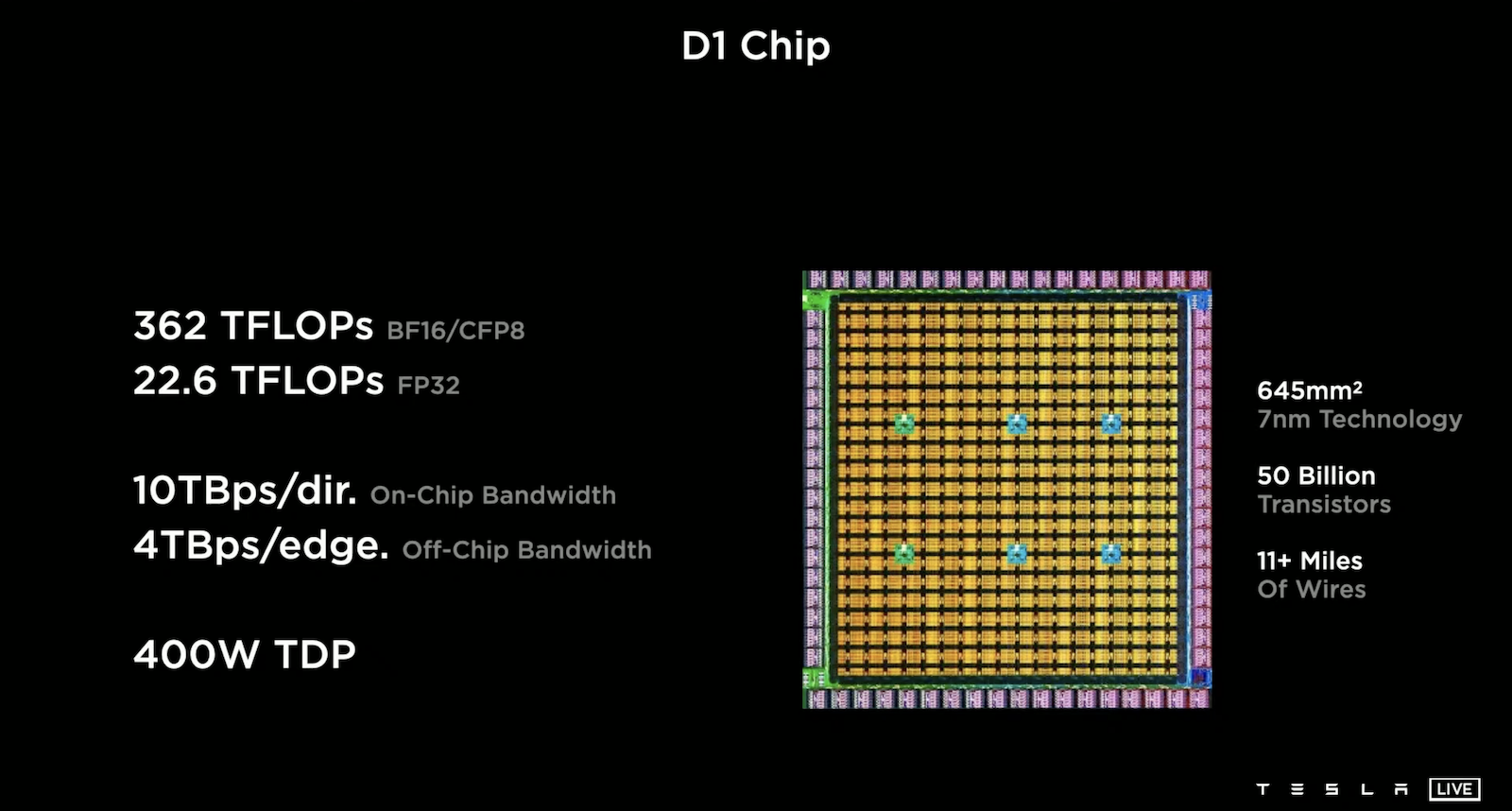
集成354個 Training Node,就得到中間黃色的計算陣列。在計算陣列周圍使用了576個高速低功耗的SerDes圍繞,使得該晶片擁有極高的I/O帶寬。結合這些就得到了 D1 Chip ,其採用 7 nm 製程,在645平方毫米下可容納500億個電晶體。
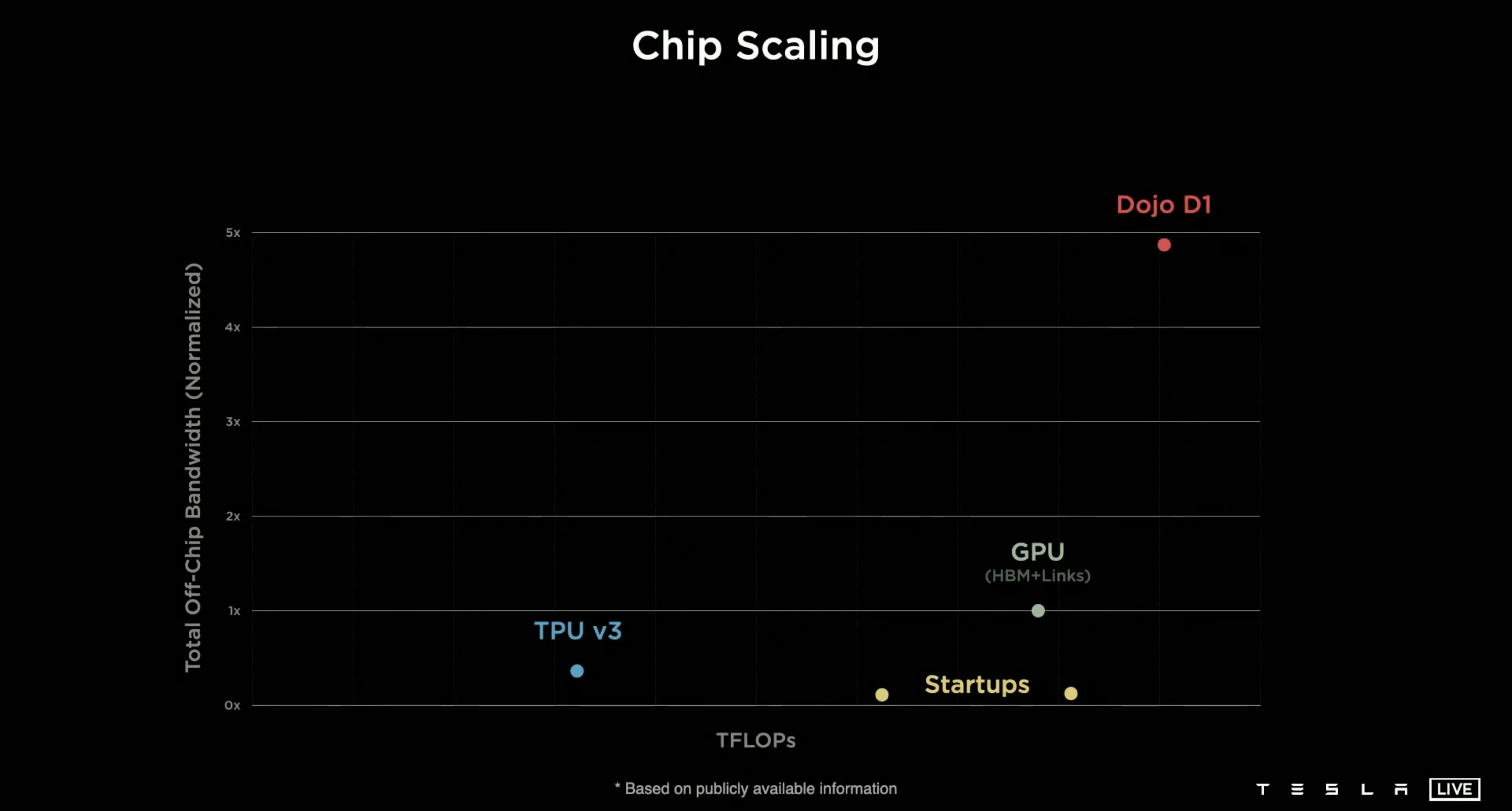
Dojo D1幾乎是業界第一。
含有多個Dojo D1的集成電路,可提供每秒9萬億次的浮點計算(FLOP)。
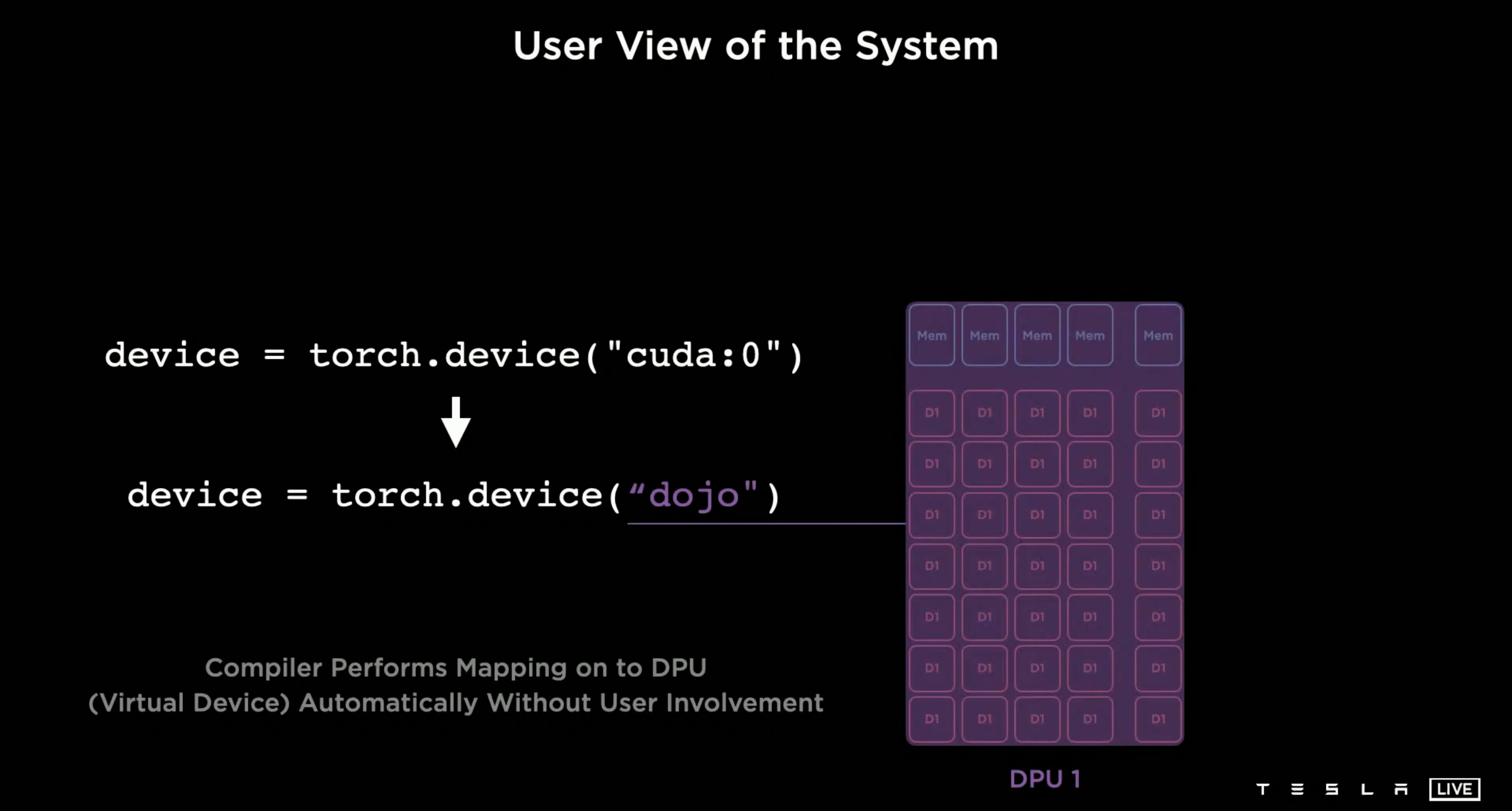
得益於 Tesla 構建的強大的編譯器,只需要少許的改動原本的 Pytorch 就可以使用 Dojo。
Tesla Bot — Optimus
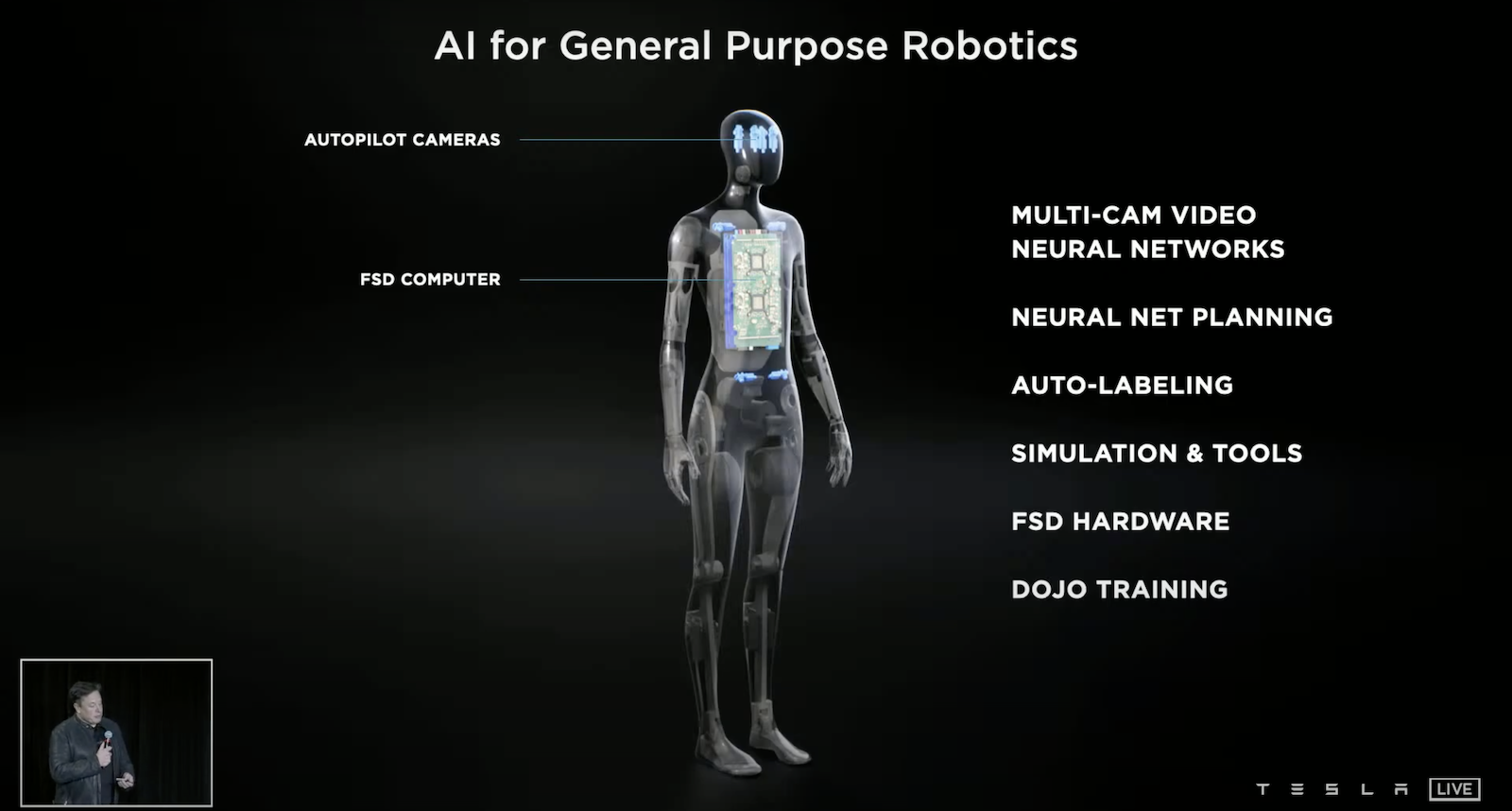
Tesla 將打造機器人,他們想延伸自動駕駛上面技術來打造一個通用機器人。
我的觀點
- End-to-end 是個重要的趨勢,當預測目標與真實目標貼近時往往表現得更好。Tesla 一開始嘗試想從影像的預測去推算出 Vector Space 的預測,但因為誤差累積的緣故,無法得到好的預測結果,當他們採用 End-to-end 直接預測在 Vector Space 後才得以解決問題。
- 讓模型合理的掌握所有資訊是重要的,例如在這裡:綜合八顆鏡頭的影像、在時間尺度和空間尺度上讓模型使用這些上下文的資訊。
- Tesla 將自己打造成一家資料公司,當資料愈多,訓練出來的模型就越準;自動駕駛越優質,更能吸引市場大眾購買他們的電動車,又反過來增強他們的資料,這形成一個良性循環。
- 為了有效的利用龐大的資料,Tesla 發展了 Auto Labeling 的技術以及打造超級電腦 Dojo,這同樣形成一個良性循環,Auto Labeling 讓標注速度大幅度提升,可以快速迭代模型;而模型更準確,Auto Labeling 的重建技術就越準確。在這個循環下,Tesla 可以漸漸的不需要那麼多標注人員。
- Auto Labeling 技術應該是推動這整個專案最重要的技術。
- 你是否有發現 Tesla 幾乎從頭打造開發自動駕駛的一切,晶片自己設計、集成電路自己打造、編譯器自己設計、標注軟體自行打造、創造自己的模擬引擎。這是 Musk 一貫的方法,重新打造並精練整個開發過程,最終會帶來精準打擊目標同時降低成本的效果,並且創造公司技術的護城河。
- Tesla 確實有創造可量產人形機器人的底氣在,自動駕駛技術就是電機械技術與AI的交會,而且 Tesla 還懂得如何降低成本及量產,善用這些Know-how來打造人形機器人是個聰明的決策,也同時創造公司的另外一個上升曲線。
- 原本我也是一個對於移除光雷達的懷疑者,但聽完這個演講後我漸漸能理解 Tesla 為何採用純視覺的方法,一般駕駛員也是憑藉著視覺開車,更何況 Tesla 電動車有八顆鏡頭,其視野能力已經比人還好了,並且模型的預測是經過大量資料的驗證,反觀人類開車上路前的驗證是相對少的。而配置光雷達是需要成本的,如果大量資料都在在的顯示模型的有效性,拿掉光雷達的決策也是可以理解的。
- 我覺得每個駕駛自行開車的操作也是一個重要的資訊,這場演講沒有講到他們怎麼使用這些資訊,有點想知道!